\n
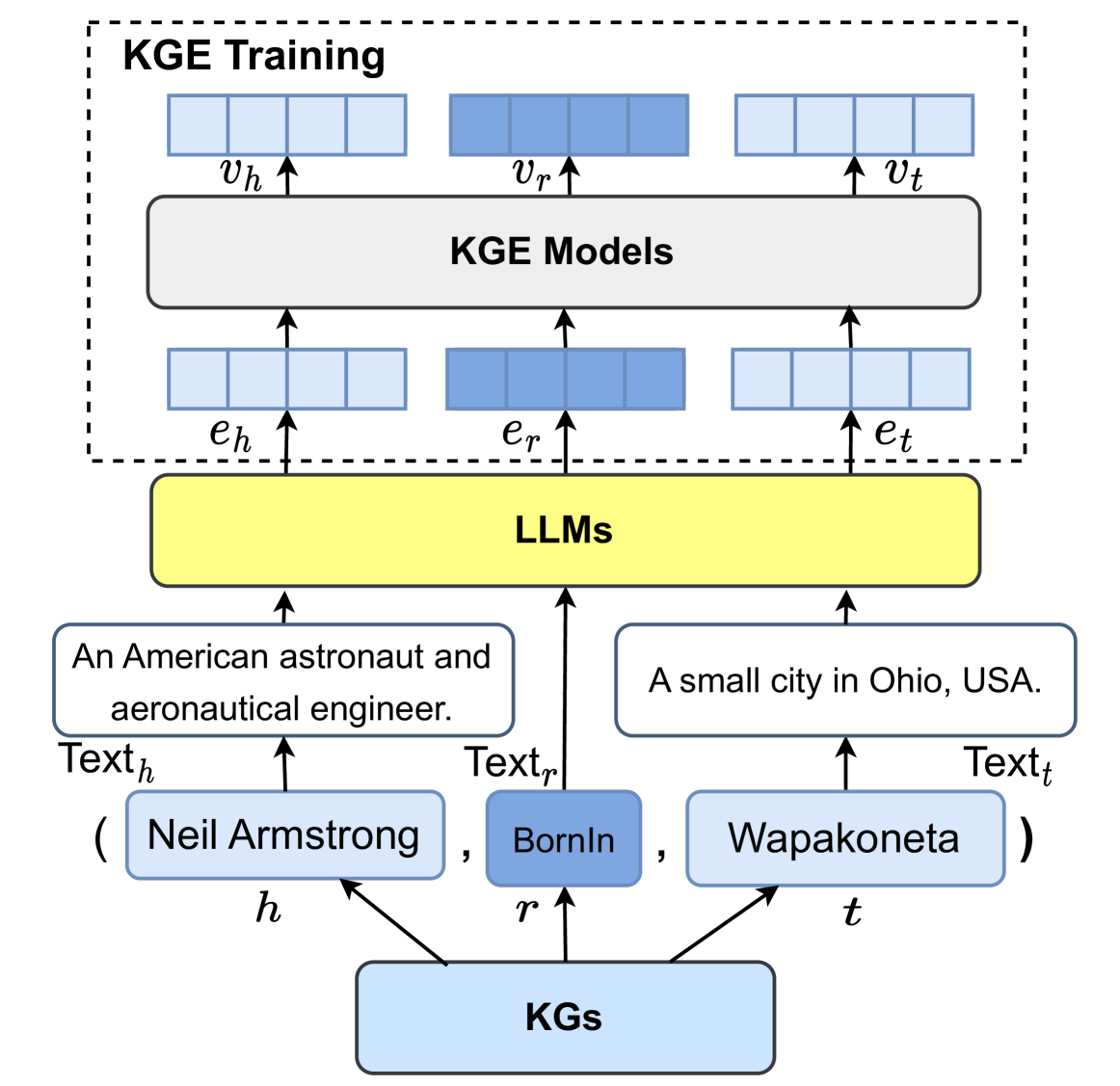
## Diagram: Knowledge Graph Enhanced (KGE) Training Architecture
### Overview
This diagram illustrates the architecture for Knowledge Graph Enhanced (KGE) training, involving Knowledge Graphs (KGs), Large Language Models (LLMs), and KGE Models. It depicts the flow of information from KGs through LLMs to KGE Models, and finally to a training phase. The diagram uses boxes and arrows to represent components and data flow.
### Components/Axes
The diagram consists of the following components:
* **KGE Training:** A dashed-border box at the top, indicating the training phase.
* **KGE Models:** A rectangular box representing the KGE models.
* **LLMs:** A yellow rectangular box representing Large Language Models.
* **KGs:** A purple rectangular box representing Knowledge Graphs.
* **Text Blocks:** Three text blocks containing descriptive information about entities and relations.
* **Arrows:** Arrows indicating the direction of data flow between components.
* **Labels:** Labels such as *v<sub>h</sub>*, *v<sub>r</sub>*, *v<sub>t</sub>*, *e<sub>h</sub>*, *e<sub>r</sub>*, *e<sub>t</sub>*, *Text<sub>h</sub>*, *Text<sub>r</sub>*, *Text<sub>t</sub>*, *h*, *r*, *t*.
### Detailed Analysis or Content Details
The diagram shows a flow of information starting from the bottom:
1. **Knowledge Graphs (KGs):** The purple box labeled "KGs" is the starting point. Three entities are represented as inputs: *h*, *r*, and *t*.
2. **Text Generation:** These entities are fed into text blocks:
* *Text<sub>h</sub>*: Contains the text "An American astronaut and aeronautical engineer. ( Neil Armstrong , BornIn )".
* *Text<sub>r</sub>*: Contains the text "BornIn".
* *Text<sub>t</sub>*: Contains the text "A small city in Ohio, USA. Wapakoneta".
3. **LLMs:** The text blocks are inputs to the yellow box labeled "LLMs".
4. **KGE Models:** The LLMs output is fed into the "KGE Models" box. The outputs are labeled *e<sub>h</sub>*, *e<sub>r</sub>*, and *e<sub>t</sub>*.
5. **KGE Training:** Finally, the outputs from the KGE Models (*e<sub>h</sub>*, *e<sub>r</sub>*, *e<sub>t</sub>*) are fed into the "KGE Training" phase, represented by the top dashed box. The outputs from the KGE Models are labeled *v<sub>h</sub>*, *v<sub>r</sub>*, and *v<sub>t</sub>*.
The arrows indicate a unidirectional flow of information from bottom to top. The labels *h*, *r*, and *t* likely represent head entity, relation, and tail entity, respectively, in the knowledge graph. The labels *v* and *e* likely represent vector embeddings.
### Key Observations
The diagram highlights a pipeline for enhancing knowledge graphs using large language models. The LLMs appear to be used to generate textual representations of entities and relations, which are then used to train KGE models. The KGE training phase likely involves optimizing the embeddings of entities and relations based on the LLM-generated text.
### Interpretation
This diagram illustrates a method for incorporating textual information from LLMs into knowledge graph embeddings. The LLMs provide a rich textual context for the entities and relations in the knowledge graph, which can improve the quality of the embeddings. This approach could be useful for tasks such as knowledge graph completion, entity linking, and relation extraction. The diagram suggests a process of converting symbolic knowledge (KGs) into a format understandable by LLMs (text), and then back into a structured representation (KGE models). The use of embeddings (*v* and *e* labels) suggests that the KGE models are likely based on vector space representations of knowledge. The diagram does not provide any specific details about the training process or the architecture of the LLMs or KGE models. It is a high-level overview of the system.