## Diagram: Mask Entity Prediction
### Overview
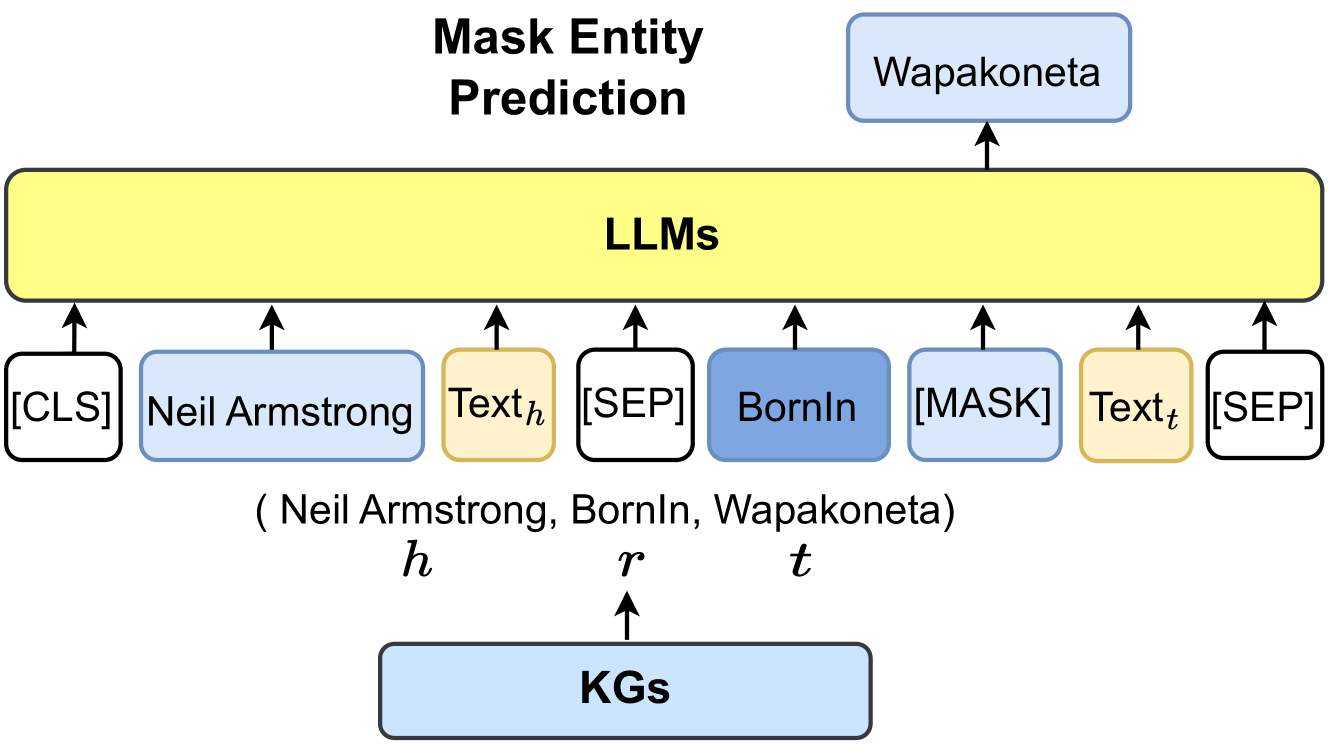
The image is a diagram illustrating a "Mask Entity Prediction" process using Large Language Models (LLMs) and Knowledge Graphs (KGs). It shows how LLMs are used to predict a masked entity based on input text and knowledge from KGs.
### Components/Axes
* **Title:** Mask Entity Prediction
* **Top Box:** "Wapakoneta" (light blue box with rounded corners)
* **Central Box:** "LLMs" (large yellow box with rounded corners)
* **Bottom Box:** "KGs" (light blue box with rounded corners)
* **Input Boxes (from left to right):**
* "[CLS]" (white box with black border and rounded corners)
* "Neil Armstrong" (light blue box with rounded corners)
* "Textₕ" (light orange box with rounded corners)
* "[SEP]" (white box with black border and rounded corners)
* "BornIn" (light blue box with rounded corners)
* "[MASK]" (white box with black border and rounded corners)
* "Textₜ" (light orange box with rounded corners)
* "[SEP]" (white box with black border and rounded corners)
* **Labels below input boxes:**
* "(Neil Armstrong, BornIn, Wapakoneta)"
* "h" (below "Neil Armstrong")
* "r" (below "BornIn")
* "t" (below "[MASK]")
* **Arrows:** Arrows indicate the flow of information. Arrows point upwards from the input boxes to the "LLMs" box, from the "KGs" box to "r", and from the "LLMs" box to "Wapakoneta".
### Detailed Analysis or Content Details
The diagram depicts a process where LLMs are used to predict a masked entity. The input consists of:
1. A classification token "[CLS]".
2. The entity "Neil Armstrong" (labeled as 'h').
3. Text context "Textₕ".
4. A separator token "[SEP]".
5. The relation "BornIn" (labeled as 'r').
6. A mask token "[MASK]".
7. Text context "Textₜ".
8. A separator token "[SEP]".
The LLMs use this input, along with information from Knowledge Graphs (KGs), to predict the masked entity, which in this case is "Wapakoneta" (labeled as 't'). The tuple (Neil Armstrong, BornIn, Wapakoneta) is shown below the input boxes, indicating the relationship being predicted.
### Key Observations
* The diagram illustrates a knowledge graph completion task where the LLM predicts the missing entity in a triple.
* The input sequence includes special tokens like "[CLS]", "[SEP]", and "[MASK]" which are common in transformer-based models.
* The colors of the boxes seem to indicate different types of information: light blue for entities, light orange for text, and white for special tokens.
### Interpretation
The diagram demonstrates how LLMs can be used for knowledge graph completion tasks. By providing the LLM with context, a relation, and a masked entity, the model can predict the missing entity based on its learned knowledge and the information provided by the KGs. This process is useful for expanding and completing knowledge graphs, as well as for tasks such as question answering and information retrieval. The use of special tokens helps the LLM understand the structure of the input and focus on the relevant information for prediction.