\n
## Diagram: Mask Entity Prediction Workflow
### Overview
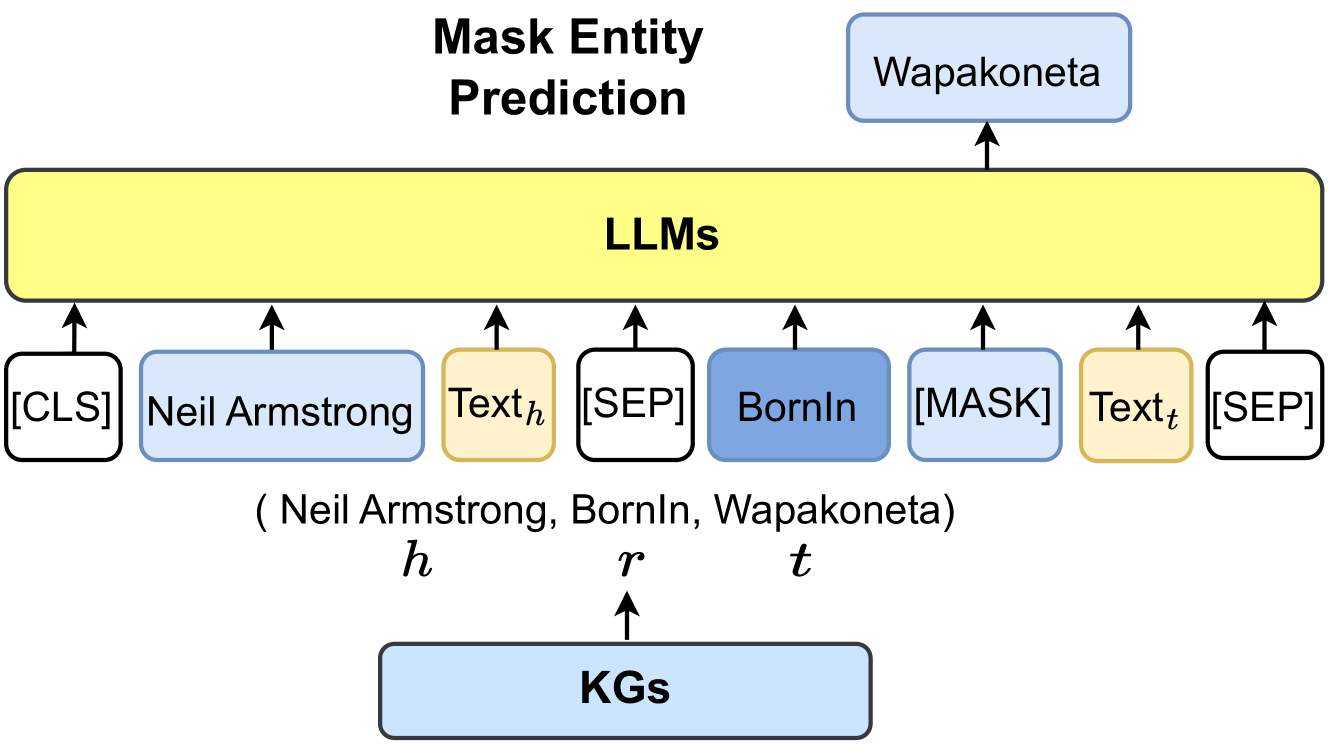
This diagram illustrates a workflow for Mask Entity Prediction, utilizing Large Language Models (LLMs) and Knowledge Graphs (KGs). The process involves feeding information from KGs into LLMs to predict masked entities.
### Components/Axes
The diagram consists of the following components:
* **Title:** "Mask Entity Prediction" (Top-center)
* **LLMs:** A large yellow rectangle representing Large Language Models (Center)
* **KGs:** A light blue rectangle representing Knowledge Graphs (Bottom-center)
* **Input Tokens:** Several light blue rectangles representing input tokens: "[CLS]", "Neil Armstrong", "Text<sub>h</sub>", "[SEP]", "BornIn", "[MASK]", "Text<sub>t</sub>", "[SEP]" (Bottom, feeding into LLMs)
* **Output Entity:** A light blue rectangle representing the predicted entity: "Wapakoneta" (Top-right, output from LLMs)
* **Triplet Representation:** "(Neil Armstrong, BornIn, Wapakoneta)" with labels *h*, *r*, and *t* (Below the LLMs and above KGs)
### Detailed Analysis or Content Details
The diagram depicts a data flow:
1. **Knowledge Graphs (KGs)** provide information.
2. This information is used to construct a triplet representation: (Neil Armstrong, BornIn, Wapakoneta).
3. The triplet is represented as *h* (head entity - Neil Armstrong), *r* (relation - BornIn), and *t* (tail entity - Wapakoneta).
4. The triplet is then transformed into a sequence of tokens: "[CLS]", "Neil Armstrong", "Text<sub>h</sub>", "[SEP]", "BornIn", "[MASK]", "Text<sub>t</sub>", "[SEP]".
5. These tokens are fed into the **Large Language Models (LLMs)**.
6. The LLMs process the input and predict the masked entity, which is "Wapakoneta".
7. The predicted entity is outputted.
The tokens are arranged horizontally, feeding into the LLMs from the bottom. The LLMs are represented as a single block, and the output "Wapakoneta" is shown above the LLMs. Arrows indicate the direction of data flow.
### Key Observations
The diagram highlights the use of KGs to provide structured knowledge to LLMs for entity prediction. The "[MASK]" token indicates that the LLM is tasked with filling in the missing entity in the triplet. The use of special tokens like "[CLS]" and "[SEP]" suggests the LLM is likely a transformer-based model.
### Interpretation
This diagram illustrates a common approach to knowledge-enhanced language understanding. By leveraging structured knowledge from KGs, LLMs can improve their ability to reason about entities and relationships. The "Mask Entity Prediction" task is a specific application of this approach, where the LLM is trained to predict missing entities in knowledge triplets. The diagram suggests a pipeline where KGs provide the factual basis, and LLMs provide the reasoning capabilities. The use of a masked entity prediction task is a standard technique for evaluating the LLM's understanding of knowledge and its ability to integrate it with linguistic context. The subscript 'h' and 't' likely denote head and tail entities respectively, common terminology in knowledge graph embeddings.