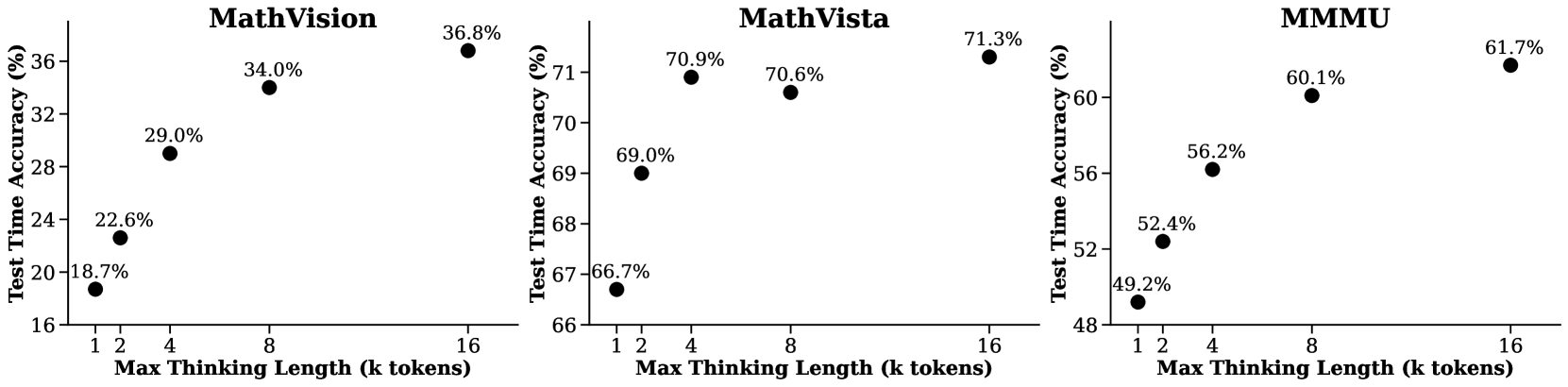
## Scatter Plot: Test Time Accuracy vs. Max Thinking Length for MathVision, MathVista, and MMMU
### Overview
The image presents three scatter plots comparing the test time accuracy (in percentage) against the maximum thinking length (in k tokens) for three different models: MathVision, MathVista, and MMMU. Each plot shows how the accuracy changes as the maximum thinking length increases.
### Components/Axes
* **X-axis (Horizontal):** Max Thinking Length (k tokens). The axis markers are at 1, 2, 4, 8, and 16.
* **Y-axis (Vertical):** Test Time Accuracy (%). The scale varies for each plot to best display the data.
* **MathVision:** Ranges from 16% to 36%.
* **MathVista:** Ranges from 66% to 71%.
* **MMMU:** Ranges from 48% to 62%.
* **Data Points:** Black dots representing the accuracy at specific thinking lengths. Each data point is labeled with its corresponding accuracy percentage.
* **Titles:** Each plot has a title indicating the model being evaluated: MathVision, MathVista, and MMMU.
### Detailed Analysis
**MathVision:**
* **Trend:** The test time accuracy generally increases as the maximum thinking length increases.
* **Data Points:**
* 1k tokens: 18.7%
* 2k tokens: 22.6%
* 4k tokens: 29.0%
* 8k tokens: 34.0%
* 16k tokens: 36.8%
**MathVista:**
* **Trend:** The test time accuracy increases sharply from 1k to 4k tokens, then plateaus.
* **Data Points:**
* 1k tokens: 66.7%
* 2k tokens: 69.0%
* 4k tokens: 70.9%
* 8k tokens: 70.6%
* 16k tokens: 71.3%
**MMMU:**
* **Trend:** The test time accuracy increases as the maximum thinking length increases.
* **Data Points:**
* 1k tokens: 49.2%
* 2k tokens: 52.4%
* 4k tokens: 56.2%
* 8k tokens: 60.1%
* 16k tokens: 61.7%
### Key Observations
* MathVista has the highest test time accuracy overall, with values consistently above 66%.
* MathVision has the lowest initial accuracy (18.7% at 1k tokens) but shows a substantial increase with longer thinking lengths.
* MMMU shows a steady increase in accuracy as the thinking length increases, but its overall accuracy remains lower than MathVista.
* All three models show diminishing returns in accuracy gains as the thinking length increases from 8k to 16k tokens.
### Interpretation
The plots suggest that increasing the maximum thinking length generally improves the test time accuracy for all three models. However, the extent of improvement varies. MathVista appears to benefit the most from a thinking length of up to 4k tokens, after which the gains are minimal. MathVision and MMMU show more consistent improvements across the range of thinking lengths tested, although the rate of improvement slows down at higher values.
The data indicates that there is a trade-off between the computational cost of longer thinking lengths and the resulting accuracy gains. Depending on the specific application and resource constraints, different models and thinking lengths may be optimal. MathVista might be preferred for applications where high accuracy is crucial and computational resources are limited, while MathVision and MMMU might be suitable for scenarios where incremental improvements in accuracy are valuable and more computational resources are available.