\n
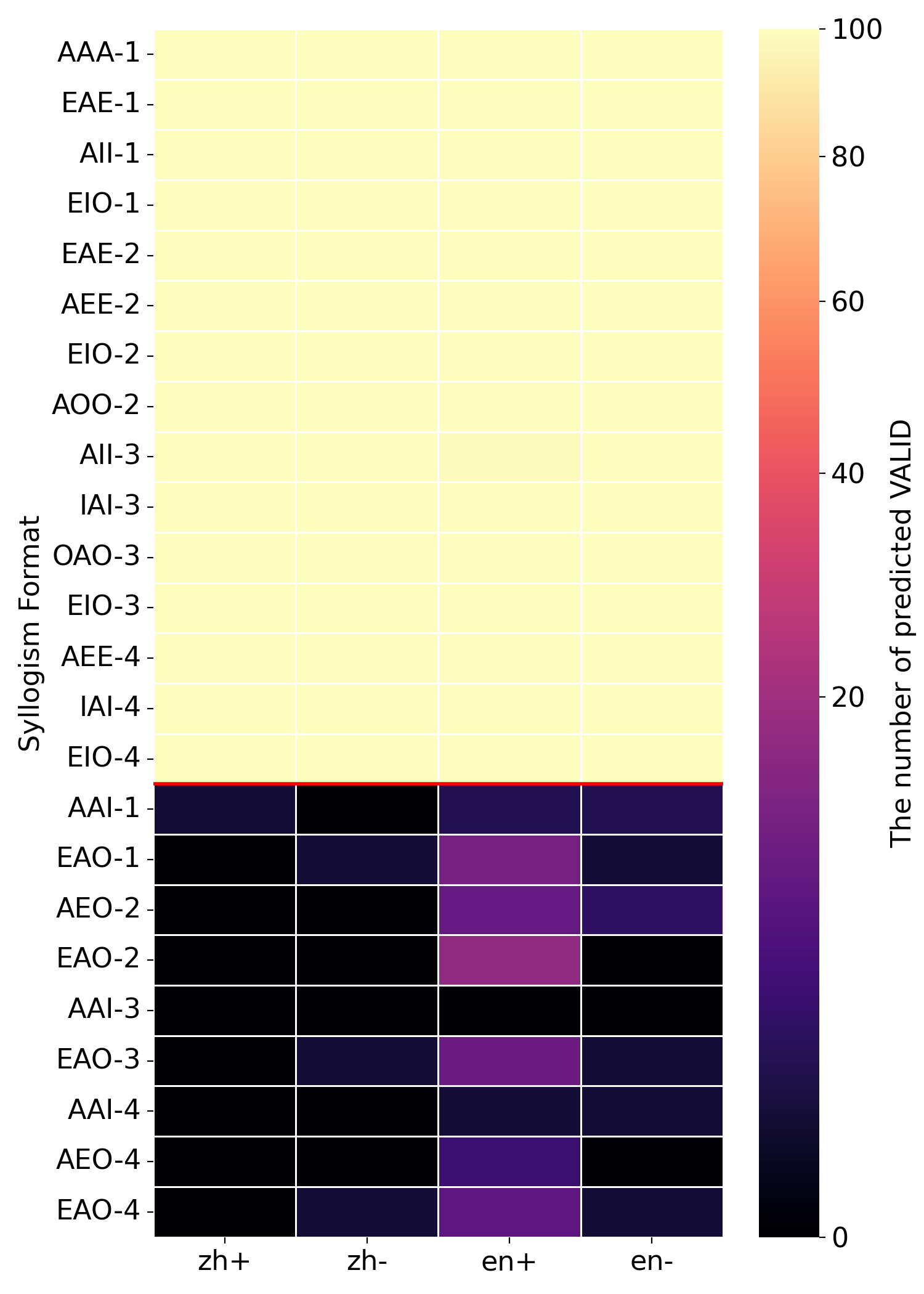
## Heatmap: Syllogism Format Validity Prediction Counts
### Overview
This image presents a heatmap visualizing the number of predicted VALID syllogisms for different syllogism formats and language combinations. The heatmap uses a color gradient to represent the count, ranging from 0 (dark purple) to 100 (light yellow). The x-axis represents language combinations, and the y-axis represents syllogism formats.
### Components/Axes
* **X-axis:** Language Combination. Categories are: "zh+" (Chinese positive), "zh-" (Chinese negative), "en+" (English positive), "en-" (English negative).
* **Y-axis:** Syllogism Format. Categories are: AAA-1, EAE-1, AII-1, EIO-1, EAE-2, AEE-2, EIO-2, AOO-2, AII-3, IAI-3, OAO-3, EIO-3, AEE-4, IAI-4, EIO-4, AAI-1, EAO-1, AEO-2, EAO-2, AAI-3, EAO-3, AAI-4, AEO-4, EAO-4.
* **Color Scale:** Represents "The number of predicted VALID". The scale ranges from dark purple (approximately 0) to light yellow (approximately 100).
* **Legend:** Located on the right side of the heatmap, showing the color gradient and corresponding numerical values.
### Detailed Analysis
The heatmap displays the counts of predicted valid syllogisms for each combination of syllogism format and language. The values are approximate due to the visual nature of the data extraction.
Here's a breakdown of the data, row by row, with approximate values:
* **AAA-1:** zh+ ~ 90, zh- ~ 85, en+ ~ 80, en- ~ 75
* **EAE-1:** zh+ ~ 85, zh- ~ 80, en+ ~ 75, en- ~ 70
* **AII-1:** zh+ ~ 80, zh- ~ 75, en+ ~ 70, en- ~ 65
* **EIO-1:** zh+ ~ 75, zh- ~ 70, en+ ~ 65, en- ~ 60
* **EAE-2:** zh+ ~ 70, zh- ~ 65, en+ ~ 60, en- ~ 55
* **AEE-2:** zh+ ~ 65, zh- ~ 60, en+ ~ 55, en- ~ 50
* **EIO-2:** zh+ ~ 60, zh- ~ 55, en+ ~ 50, en- ~ 45
* **AOO-2:** zh+ ~ 55, zh- ~ 50, en+ ~ 45, en- ~ 40
* **AII-3:** zh+ ~ 50, zh- ~ 45, en+ ~ 40, en- ~ 35
* **IAI-3:** zh+ ~ 45, zh- ~ 40, en+ ~ 35, en- ~ 30
* **OAO-3:** zh+ ~ 40, zh- ~ 35, en+ ~ 30, en- ~ 25
* **EIO-3:** zh+ ~ 35, zh- ~ 30, en+ ~ 25, en- ~ 20
* **AEE-4:** zh+ ~ 30, zh- ~ 25, en+ ~ 20, en- ~ 15
* **IAI-4:** zh+ ~ 25, zh- ~ 20, en+ ~ 15, en- ~ 10
* **EIO-4:** zh+ ~ 20, zh- ~ 15, en+ ~ 10, en- ~ 5
* **AAI-1:** zh+ ~ 15, zh- ~ 10, en+ ~ 5, en- ~ 0
* **EAO-1:** zh+ ~ 10, zh- ~ 5, en+ ~ 0, en- ~ 0
* **AEO-2:** zh+ ~ 5, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-2:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AAI-3:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-3:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AAI-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **AEO-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
* **EAO-4:** zh+ ~ 0, zh- ~ 0, en+ ~ 0, en- ~ 0
**Trends:**
* Generally, the counts of predicted valid syllogisms decrease as the syllogism format number increases (e.g., from -1 to -4).
* The counts are generally higher for "zh+" (Chinese positive) compared to "en-" (English negative).
* The counts are higher for positive language combinations ("zh+" and "en+") than for negative language combinations ("zh-" and "en-").
### Key Observations
* The bottom rows (AAI-1 through EAO-4) consistently show very low or zero counts of predicted valid syllogisms, regardless of the language.
* The highest counts are observed for the AAA-1 format in the "zh+" language combination, reaching approximately 90.
* There's a clear gradient across the heatmap, indicating a strong relationship between syllogism format, language, and predicted validity.
### Interpretation
This heatmap suggests that the model used to predict syllogism validity performs better on certain syllogism formats and language combinations than others. The higher counts for "zh+" and lower counts for "en-" might indicate a bias in the model towards Chinese language or a difference in the way syllogisms are structured or interpreted in the two languages. The decreasing counts as the format number increases suggest that more complex syllogism formats are harder for the model to validate. The consistent low counts for the bottom rows indicate that these formats are rarely predicted as valid, potentially due to inherent logical flaws or difficulties in parsing them. This data could be used to improve the model by focusing on the formats and languages where it performs poorly, or by investigating the reasons for the observed biases. The use of "+" and "-" in the language labels suggests a possible sentiment or polarity component being considered in the validation process, which warrants further investigation.