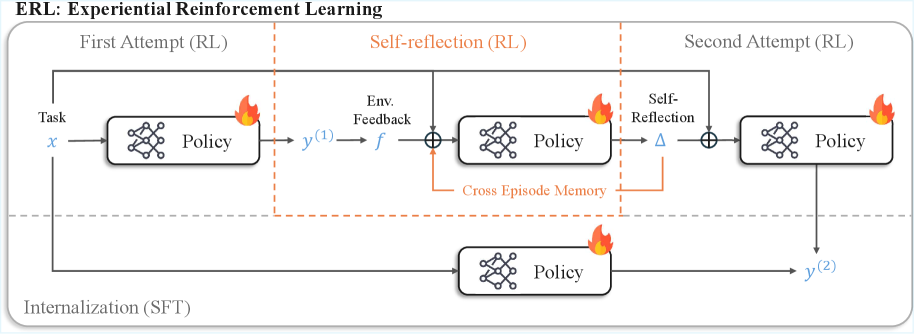
## Diagram: Experiential Reinforcement Learning (ERL)
### Overview
The image is a diagram illustrating the Experiential Reinforcement Learning (ERL) process. It shows a system that learns through multiple attempts, incorporating self-reflection and internalization. The diagram is divided into three main stages: First Attempt (RL), Self-reflection (RL), and Second Attempt (RL), with an additional path for Internalization (SFT).
### Components/Axes
* **Title:** ERL: Experiential Reinforcement Learning
* **Stages:**
* First Attempt (RL) - Top-left
* Self-reflection (RL) - Top-center
* Second Attempt (RL) - Top-right
* Internalization (SFT) - Bottom
* **Elements:**
* Task: x (input to the first policy)
* Policy: Represented by a rounded rectangle containing a neural network symbol.
* Env. Feedback: f (Environment Feedback)
* Self-Reflection: Δ (Delta symbol)
* Cross Episode Memory: An orange line connecting the output of the "Self-reflection (RL)" stage to the input of the "First Attempt (RL)" stage.
* y^(1): Output of the first policy.
* y^(2): Output of the second policy.
* Summation symbols: Represented by a circle with a plus sign inside.
* Fire symbols: Located on the top right of each policy box.
### Detailed Analysis or ### Content Details
1. **First Attempt (RL):**
* A "Task" labeled as 'x' is input into a "Policy" block.
* The output of the "Policy" block is labeled 'y^(1)'.
* A fire symbol is located on the top right of the policy box.
2. **Self-reflection (RL):**
* The output 'y^(1)' is transformed by "Env. Feedback" labeled as 'f'.
* The transformed output is then summed with a "Cross Episode Memory" signal (orange line).
* The result is input into another "Policy" block.
* The output of this "Policy" block is summed with "Self-Reflection" labeled as 'Δ'.
* A fire symbol is located on the top right of the policy box.
3. **Second Attempt (RL):**
* The summed output from the "Self-reflection (RL)" stage is input into another "Policy" block.
* The output of this "Policy" block is labeled 'y^(2)'.
* A fire symbol is located on the top right of the policy box.
4. **Internalization (SFT):**
* The initial "Task" 'x' is also input into a "Policy" block in the "Internalization (SFT)" path.
* The output of this "Policy" block is 'y^(2)', which is the same output as the "Second Attempt (RL)" stage.
* A fire symbol is located on the top right of the policy box.
5. **Cross Episode Memory:**
* An orange line labeled "Cross Episode Memory" connects the output of the "Self-reflection (RL)" stage to the input of the summation symbol in the "Self-reflection (RL)" stage.
### Key Observations
* The diagram illustrates a multi-stage learning process with feedback loops.
* The "Cross Episode Memory" suggests a mechanism for retaining information across different attempts.
* The "Internalization (SFT)" path provides an alternative route to achieve the same output 'y^(2)'.
* The fire symbols located on the top right of each policy box are not explained.
### Interpretation
The diagram depicts a reinforcement learning system that refines its policy through multiple attempts and self-reflection. The "Cross Episode Memory" allows the system to leverage past experiences to improve future performance. The "Internalization (SFT)" path might represent a more direct or efficient way to achieve the desired outcome, potentially bypassing the iterative learning process. The fire symbols are not explained, but may represent a cost or risk associated with each policy. The system appears to learn from its mistakes and adapt its strategy over time, ultimately converging towards a more effective policy.