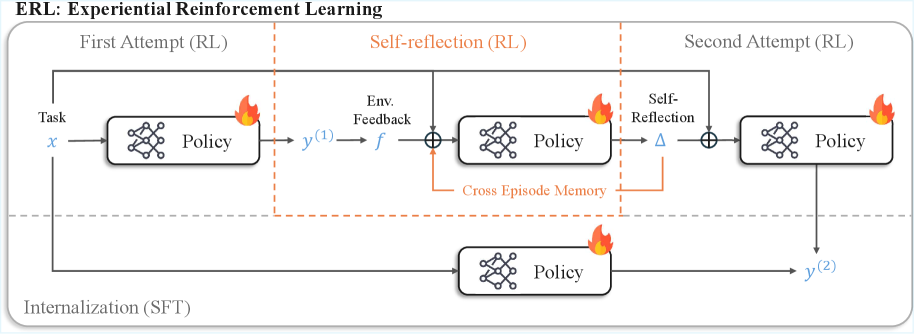
## Diagram: ERL: Experiential Reinforcement Learning
### Overview
The image is a technical flowchart illustrating a machine learning framework called "ERL: Experiential Reinforcement Learning." It depicts a multi-stage process for training a policy model, involving initial reinforcement learning (RL), a self-reflection phase, a second RL attempt, and a final internalization step via supervised fine-tuning (SFT). The diagram uses boxes, arrows, mathematical symbols, and icons to represent components, data flow, and learning mechanisms.
### Components/Axes
The diagram is organized into two primary horizontal rows, separated by a dashed gray line.
**Top Row (Three-Phase RL Process):**
This row is divided into three sequential phases by vertical dashed orange lines.
1. **First Attempt (RL):** The initial phase.
2. **Self-reflection (RL):** The middle, reflective phase. This section's title and its internal dashed box are colored orange.
3. **Second Attempt (RL):** The final RL phase.
**Bottom Row (Internalization):**
1. **Internalization (SFT):** A parallel process that runs concurrently with the top row's sequence.
**Key Components & Symbols:**
* **Policy Boxes:** Rectangular boxes labeled "Policy," each containing a network graph icon (three interconnected nodes) and a flame icon (🔥) in the top-right corner. There are four such boxes in total.
* **Arrows:** Solid black arrows indicate the primary flow of data and control.
* **Mathematical Symbols:**
* `x`: The input task.
* `y^(1)`: The output from the first policy attempt.
* `f`: Represents "Env. Feedback" (Environment Feedback).
* `⊕`: A summation or combination node (circle with a plus sign).
* `Δ`: Represents "Self-Reflection."
* `y^(2)`: The final output from the second policy attempt.
* **Text Labels:**
* "Task" (pointing to `x`).
* "Env. Feedback" (pointing to `f`).
* "Cross Episode Memory" (within an orange dashed box, pointing to a combination node).
* "Self-Reflection" (pointing to `Δ`).
### Detailed Analysis
The process flow is as follows:
**1. First Attempt (RL):**
* A task `x` is input into the first "Policy" model.
* This policy produces an initial output `y^(1)`.
**2. Self-reflection (RL):**
* The output `y^(1)` receives "Env. Feedback" `f`.
* This feedback (`f`) and the original task `x` are combined at a summation node (`⊕`).
* The combined signal is fed into a second "Policy" model.
* This policy generates a "Self-Reflection" signal `Δ`.
* **Crucially, there is a feedback loop:** The `Δ` signal is routed back via "Cross Episode Memory" to the summation node that feeds the *same* policy, creating an iterative refinement loop within this phase.
**3. Second Attempt (RL):**
* The original task `x` and the self-reflection signal `Δ` are combined at another summation node (`⊕`).
* This combined input is fed into a third "Policy" model.
* This final policy produces the output `y^(2)`.
**4. Internalization (SFT):**
* Running in parallel, the original task `x` is also fed directly into a fourth "Policy" model located in the bottom row.
* This policy's output is also `y^(2)`, indicating it produces the same final output as the top-row process. This suggests the knowledge or policy from the RL process is being "internalized" or distilled into a standalone model via Supervised Fine-Tuning (SFT).
### Key Observations
* **Iterative Refinement:** The "Self-reflection (RL)" phase is not a single step but contains an internal loop where the policy's own reflection (`Δ`) is fed back to improve itself, leveraging "Cross Episode Memory."
* **Two Pathways to Final Output:** The final output `y^(2)` is generated by two distinct pathways: the complex, multi-stage RL+Self-Reflection pipeline (top row) and a direct SFT pathway (bottom row). This implies the SFT model is trained to mimic the behavior of the fully refined RL policy.
* **Policy Iconography:** Every "Policy" box is marked with a flame icon (🔥), which commonly symbolizes an active, trained, or "hot" model in machine learning diagrams.
* **Color Coding:** Orange is used exclusively to highlight the "Self-reflection" phase and its associated memory component, emphasizing its central, distinctive role in the ERL framework.
### Interpretation
This diagram outlines a sophisticated reinforcement learning methodology designed to overcome the limitations of standard, single-attempt RL. The core innovation is the **"Self-reflection" phase**, which acts as an introspective correction mechanism. Instead of learning only from external environment feedback (`f`), the policy learns to generate and utilize its own internal critique (`Δ`), stored in a cross-episode memory, to iteratively refine its approach *before* committing to a final second attempt.
The parallel "Internalization (SFT)" pathway suggests a practical deployment strategy. The complex, computationally expensive ERL process (with its memory and reflection loops) is used to generate high-quality training data (`y^(2)` given `x`). A separate, likely simpler, policy model is then trained via supervised learning on this data. This allows the final deployed model to benefit from the advanced reasoning of ERL without requiring the reflection machinery to run in real-time.
In essence, ERL frames learning not as a single trial, but as a cycle of **action, feedback, introspection, and re-action**, followed by **knowledge distillation**. This mimics a more human-like learning process where experience is not just accumulated but actively reflected upon to improve future performance.