## Bar Charts: LLM Performance Comparison
### Overview
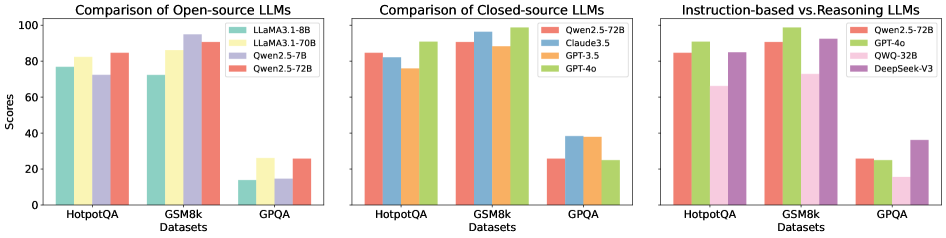
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) on three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, presumably accuracy or a similar metric, ranging from 0 to 100.
### Components/Axes
* **Titles:**
* Left Chart: "Comparison of Open-source LLMs"
* Middle Chart: "Comparison of Closed-source LLMs"
* Right Chart: "Instruction-based vs. Reasoning LLMs"
* **Y-axis:**
* Label: "Scores"
* Scale: 0 to 100, with tick marks at 20, 40, 60, 80, and 100.
* **X-axis:**
* Label: "Datasets"
* Categories: HotpotQA, GSM8k, GPQA
* **Legends:**
* **Left Chart (Open-source):** Located at the top-right of the chart.
* Light Green: "LLaMA3.1-8B"
* Yellow: "LLaMA3.1-70B"
* Lavender: "Qwen2.5-7B"
* Salmon: "Qwen2.5-72B"
* **Middle Chart (Closed-source):** Located at the top-right of the chart.
* Salmon: "Qwen2.5-72B"
* Light Blue: "Claude3.5"
* Orange: "GPT-3.5"
* Light Green: "GPT-4o"
* **Right Chart (Instruction-based vs. Reasoning):** Located at the top-right of the chart.
* Salmon: "Qwen2.5-72B"
* Light Green: "GPT-4o"
* Pink: "QWQ-32B"
* Lavender: "DeepSeek-V3"
### Detailed Analysis
**Left Chart: Comparison of Open-source LLMs**
* **HotpotQA Dataset:**
* LLaMA3.1-8B (Light Green): Approximately 77
* LLaMA3.1-70B (Yellow): Approximately 82
* Qwen2.5-7B (Lavender): Approximately 73
* Qwen2.5-72B (Salmon): Approximately 85
* **GSM8k Dataset:**
* LLaMA3.1-8B (Light Green): Approximately 73
* LLaMA3.1-70B (Yellow): Approximately 87
* Qwen2.5-7B (Lavender): Approximately 95
* Qwen2.5-72B (Salmon): Approximately 91
* **GPQA Dataset:**
* LLaMA3.1-8B (Light Green): Approximately 10
* LLaMA3.1-70B (Yellow): Approximately 25
* Qwen2.5-7B (Lavender): Approximately 10
* Qwen2.5-72B (Salmon): Approximately 25
**Middle Chart: Comparison of Closed-source LLMs**
* **HotpotQA Dataset:**
* Qwen2.5-72B (Salmon): Approximately 85
* Claude3.5 (Light Blue): Approximately 82
* GPT-3.5 (Orange): Approximately 91
* GPT-4o (Light Green): Approximately 92
* **GSM8k Dataset:**
* Qwen2.5-72B (Salmon): Approximately 98
* Claude3.5 (Light Blue): Approximately 92
* GPT-3.5 (Orange): Approximately 98
* GPT-4o (Light Green): Approximately 98
* **GPQA Dataset:**
* Qwen2.5-72B (Salmon): Approximately 25
* Claude3.5 (Light Blue): Approximately 37
* GPT-3.5 (Orange): Approximately 25
* GPT-4o (Light Green): Approximately 25
**Right Chart: Instruction-based vs. Reasoning LLMs**
* **HotpotQA Dataset:**
* Qwen2.5-72B (Salmon): Approximately 85
* GPT-4o (Light Green): Approximately 92
* QWQ-32B (Pink): Approximately 82
* DeepSeek-V3 (Lavender): Approximately 85
* **GSM8k Dataset:**
* Qwen2.5-72B (Salmon): Approximately 98
* GPT-4o (Light Green): Approximately 98
* QWQ-32B (Pink): Approximately 92
* DeepSeek-V3 (Lavender): Approximately 95
* **GPQA Dataset:**
* Qwen2.5-72B (Salmon): Approximately 25
* GPT-4o (Light Green): Approximately 25
* QWQ-32B (Pink): Approximately 15
* DeepSeek-V3 (Lavender): Approximately 32
### Key Observations
* **General Performance:** All models perform significantly better on HotpotQA and GSM8k datasets compared to GPQA.
* **Open-source Models:** Qwen2.5-72B generally outperforms LLaMA3.1 models across all datasets.
* **Closed-source Models:** GPT-4o and GPT-3.5 show very high performance on HotpotQA and GSM8k.
* **Instruction-based vs. Reasoning:** GPT-4o and Qwen2.5-72B show similar performance, while QWQ-32B and DeepSeek-V3 show slightly lower performance.
* **GPQA Challenge:** All models struggle with the GPQA dataset, indicating it is a more challenging benchmark.
### Interpretation
The charts provide a comparative analysis of various LLMs across different datasets. The data suggests that:
* **Dataset Difficulty:** GPQA is a significantly more challenging dataset for all models compared to HotpotQA and GSM8k. This could be due to the nature of the questions or the complexity of reasoning required.
* **Model Strengths:** Closed-source models like GPT-4o and GPT-3.5 demonstrate superior performance on HotpotQA and GSM8k, suggesting they are well-optimized for these types of tasks.
* **Open-source Advancements:** The Qwen2.5-72B model shows competitive performance among open-source models, indicating progress in open-source LLM development.
* **Reasoning vs. Instruction:** The Instruction-based vs. Reasoning chart suggests that while GPT-4o and Qwen2.5-72B perform similarly, other models like QWQ-32B and DeepSeek-V3 may have different strengths or weaknesses in instruction following or reasoning capabilities.
The low scores on GPQA across all model categories highlight the need for further research and development in areas such as complex reasoning and knowledge integration.