## Bar Charts: LLM Performance Comparison
### Overview
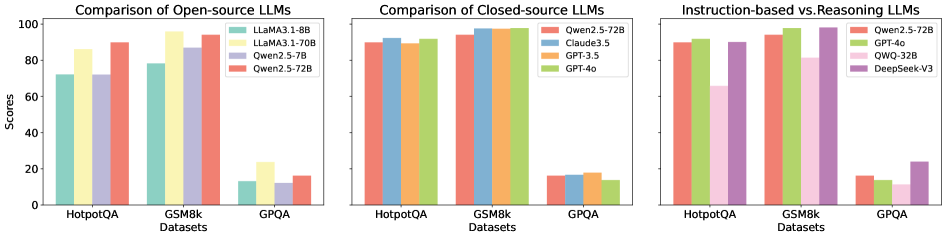
The image presents three bar charts comparing the performance of different Large Language Models (LLMs) on three datasets: HotpotQA, GSM8k, and GPQA. The charts are grouped by LLM type: Open-source, Closed-source, and Instruction-based vs. Reasoning. The y-axis represents scores, presumably accuracy or a similar performance metric.
### Components/Axes
**General Chart Elements:**
* **Title (Left Chart):** Comparison of Open-source LLMs
* **Title (Middle Chart):** Comparison of Closed-source LLMs
* **Title (Right Chart):** Instruction-based vs. Reasoning LLMs
* **Y-axis Label:** Scores
* **Y-axis Scale:** 0 to 100, with tick marks at 0, 20, 40, 60, 80, and 100.
* **X-axis Label:** Datasets
* **X-axis Categories:** HotpotQA, GSM8k, GPQA
**Legends (Top-Right of each chart):**
* **Left Chart (Open-source):**
* Light Teal: LLaMA3.1-8B
* Yellow: LLaMA3.1-70B
* Light Purple: Qwen2.5-7B
* Salmon: Qwen2.5-72B
* **Middle Chart (Closed-source):**
* Salmon: Qwen2.5-72B
* Sky Blue: Claude3.5
* Orange: GPT-3.5
* Light Green: GPT-4o
* **Right Chart (Instruction-based vs. Reasoning):**
* Salmon: Qwen2.5-72B
* Light Green: GPT-4o
* Pink: QWQ-32B
* Purple: DeepSeek-V3
### Detailed Analysis
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA Dataset:**
* LLaMA3.1-8B (Light Teal): ~72
* LLaMA3.1-70B (Yellow): ~86
* Qwen2.5-7B (Light Purple): ~72
* Qwen2.5-72B (Salmon): ~90
* **GSM8k Dataset:**
* LLaMA3.1-8B (Light Teal): ~78
* LLaMA3.1-70B (Yellow): ~96
* Qwen2.5-7B (Light Purple): ~87
* Qwen2.5-72B (Salmon): ~94
* **GPQA Dataset:**
* LLaMA3.1-8B (Light Teal): ~12
* LLaMA3.1-70B (Yellow): ~24
* Qwen2.5-7B (Light Purple): ~14
* Qwen2.5-72B (Salmon): ~18
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA Dataset:**
* Qwen2.5-72B (Salmon): ~92
* Claude3.5 (Sky Blue): ~92
* GPT-3.5 (Orange): ~92
* GPT-4o (Light Green): ~93
* **GSM8k Dataset:**
* Qwen2.5-72B (Salmon): ~97
* Claude3.5 (Sky Blue): ~97
* GPT-3.5 (Orange): ~98
* GPT-4o (Light Green): ~99
* **GPQA Dataset:**
* Qwen2.5-72B (Salmon): ~16
* Claude3.5 (Sky Blue): ~16
* GPT-3.5 (Orange): ~17
* GPT-4o (Light Green): ~13
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA Dataset:**
* Qwen2.5-72B (Salmon): ~92
* GPT-4o (Light Green): ~93
* QWQ-32B (Pink): ~88
* DeepSeek-V3 (Purple): ~92
* **GSM8k Dataset:**
* Qwen2.5-72B (Salmon): ~97
* GPT-4o (Light Green): ~99
* QWQ-32B (Pink): ~94
* DeepSeek-V3 (Purple): ~97
* **GPQA Dataset:**
* Qwen2.5-72B (Salmon): ~16
* GPT-4o (Light Green): ~13
* QWQ-32B (Pink): ~8
* DeepSeek-V3 (Purple): ~22
### Key Observations
* **General Trend:** All models perform significantly better on HotpotQA and GSM8k datasets compared to GPQA.
* **Open-source Models:** LLaMA3.1-70B and Qwen2.5-72B generally outperform LLaMA3.1-8B and Qwen2.5-7B.
* **Closed-source Models:** Performance is very similar across all closed-source models on HotpotQA and GSM8k. GPT-4o shows a slight edge on GSM8k.
* **Instruction-based vs. Reasoning Models:** GPT-4o and DeepSeek-V3 generally perform well, while QWQ-32B shows the lowest scores, especially on GPQA.
* **GPQA Challenge:** All models struggle with the GPQA dataset, indicating it is a more challenging benchmark.
### Interpretation
The charts provide a comparative analysis of LLM performance across different model architectures and datasets. The data suggests that:
* **Model Size Matters:** Larger open-source models (70B/72B) tend to outperform smaller ones (8B/7B).
* **Closed-source Models are Highly Optimized:** The closed-source models exhibit very similar and high performance on HotpotQA and GSM8k, suggesting they are well-optimized for these tasks.
* **GPQA Highlights Reasoning Gaps:** The poor performance on GPQA across all models indicates that this dataset requires more advanced reasoning capabilities that are not fully captured by current LLMs.
* **Instruction-based vs. Reasoning Trade-offs:** The performance differences between instruction-based and reasoning models on GPQA suggest potential trade-offs in model design. DeepSeek-V3 shows a relatively better performance on GPQA compared to QWQ-32B, indicating better reasoning capabilities.