## Line Charts: Scaling Operation vs. Mean Operation
### Overview
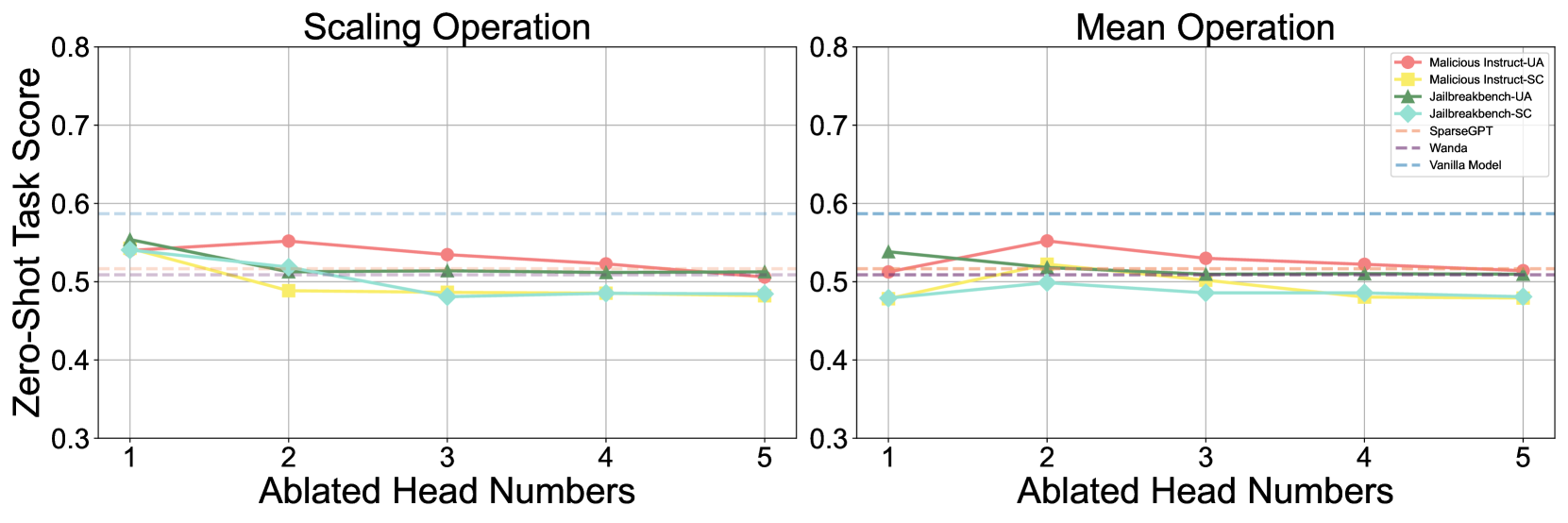
The image presents two line charts side-by-side, comparing the "Zero-Shot Task Score" against "Ablated Head Numbers" for different models under "Scaling Operation" (left) and "Mean Operation" (right). The models include "Malicious Instruct-UA," "Malicious Instruct-SC," "Jailbreakbench-UA," "Jailbreakbench-SC," "SparseGPT," "Wanda," and "Vanilla Model." The x-axis represents the number of ablated heads (1 to 5), and the y-axis represents the zero-shot task score, ranging from 0.3 to 0.8.
### Components/Axes
* **Titles:**
* Left Chart: "Scaling Operation"
* Right Chart: "Mean Operation"
* **Y-Axis Title (both charts):** "Zero-Shot Task Score"
* Scale: 0.3 to 0.8, with increments of 0.1
* **X-Axis Title (both charts):** "Ablated Head Numbers"
* Scale: 1 to 5, with increments of 1
* **Legend (located at the bottom-right of the image, shared by both charts):**
* Red Line with Circle Markers: "Malicious Instruct-UA"
* Yellow Line with Square Markers: "Malicious Instruct-SC"
* Green Line with Triangle Markers: "Jailbreakbench-UA"
* Teal Line with Diamond Markers: "Jailbreakbench-SC"
* Light Pink Dashed Line: "SparseGPT"
* Purple Dashed Line: "Wanda"
* Light Blue Dashed Line: "Vanilla Model"
### Detailed Analysis
**Left Chart: Scaling Operation**
* **Malicious Instruct-UA (Red):** Starts at approximately 0.52 at 1 ablated head, increases to approximately 0.56 at 2 ablated heads, and then gradually decreases to approximately 0.51 at 5 ablated heads.
* **Malicious Instruct-SC (Yellow):** Starts at approximately 0.50 at 1 ablated head, decreases to approximately 0.48 at 2 ablated heads, and then remains relatively stable around 0.48 to 0.49 until 5 ablated heads.
* **Jailbreakbench-UA (Green):** Starts at approximately 0.55 at 1 ablated head, decreases to approximately 0.51 at 2 ablated heads, and then remains relatively stable around 0.51 until 5 ablated heads.
* **Jailbreakbench-SC (Teal):** Starts at approximately 0.54 at 1 ablated head, decreases to approximately 0.50 at 2 ablated heads, and then remains relatively stable around 0.49 to 0.50 until 5 ablated heads.
* **SparseGPT (Light Pink Dashed):** Remains relatively stable around 0.51 to 0.52 across all ablated head numbers.
* **Wanda (Purple Dashed):** Remains relatively stable around 0.52 across all ablated head numbers.
* **Vanilla Model (Light Blue Dashed):** Remains constant at approximately 0.59 across all ablated head numbers.
**Right Chart: Mean Operation**
* **Malicious Instruct-UA (Red):** Starts at approximately 0.51 at 1 ablated head, increases to approximately 0.55 at 2 ablated heads, and then gradually decreases to approximately 0.51 at 5 ablated heads.
* **Malicious Instruct-SC (Yellow):** Starts at approximately 0.48 at 1 ablated head, increases to approximately 0.50 at 2 ablated heads, and then remains relatively stable around 0.49 until 5 ablated heads.
* **Jailbreakbench-UA (Green):** Starts at approximately 0.54 at 1 ablated head, decreases to approximately 0.52 at 2 ablated heads, and then remains relatively stable around 0.51 until 5 ablated heads.
* **Jailbreakbench-SC (Teal):** Starts at approximately 0.48 at 1 ablated head, increases to approximately 0.51 at 2 ablated heads, and then remains relatively stable around 0.50 until 5 ablated heads.
* **SparseGPT (Light Pink Dashed):** Remains relatively stable around 0.51 to 0.52 across all ablated head numbers.
* **Wanda (Purple Dashed):** Remains relatively stable around 0.52 across all ablated head numbers.
* **Vanilla Model (Light Blue Dashed):** Remains constant at approximately 0.59 across all ablated head numbers.
### Key Observations
* The "Vanilla Model" consistently scores the highest across both operations and all ablated head numbers.
* "SparseGPT" and "Wanda" models show very stable performance regardless of the number of ablated heads and the type of operation.
* "Malicious Instruct-UA" shows a slight increase in performance initially with 2 ablated heads, then decreases as more heads are ablated.
* The performance of "Malicious Instruct-SC," "Jailbreakbench-UA," and "Jailbreakbench-SC" models tends to stabilize after 2 ablated heads.
* The "Scaling Operation" and "Mean Operation" charts show similar trends for each model, with slight variations in the initial scores.
### Interpretation
The charts compare the performance of different models on a zero-shot task as the number of ablated heads increases, under two different operations: "Scaling Operation" and "Mean Operation." The "Vanilla Model" serves as a baseline, consistently outperforming the other models. The stability of "SparseGPT" and "Wanda" suggests that their performance is less sensitive to head ablation. The initial increase in performance for "Malicious Instruct-UA" with 2 ablated heads could indicate that some heads are more critical than others for this specific task. The stabilization of other models after 2 ablated heads suggests that the remaining heads are sufficient to maintain a certain level of performance. The similarity in trends between the two operations implies that the models respond similarly to head ablation regardless of the operation used.