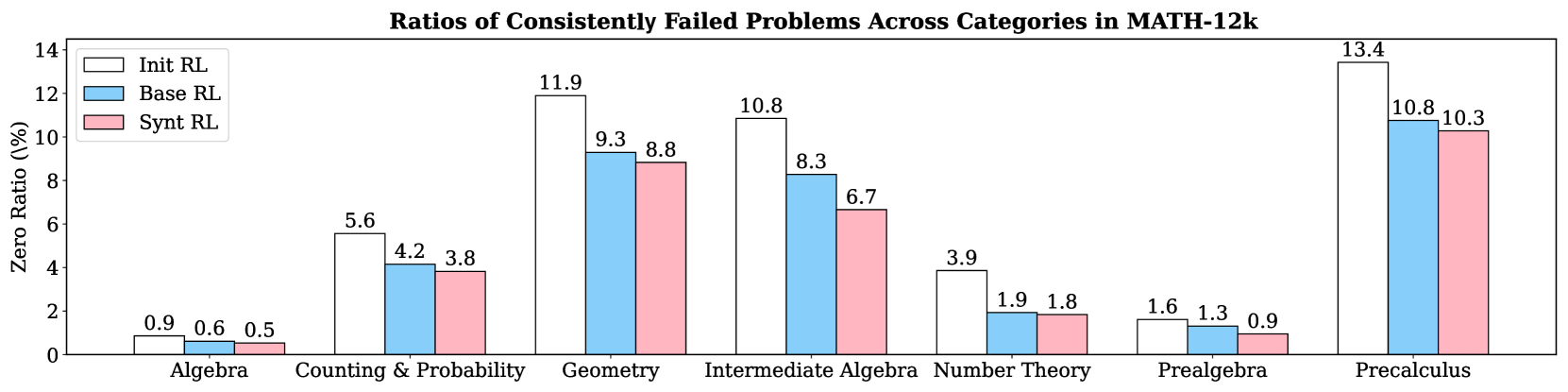
## Bar Chart: Ratios of Consistently Failed Problems Across Categories in MATH-12k
### Overview
This bar chart visualizes the ratios of consistently failed problems across different mathematical categories within the MATH-12k dataset. The chart compares three Reinforcement Learning (RL) models: "Init RL", "Base RL", and "Synt RL". The y-axis represents the "Zero Ratio" (in percentage), indicating the proportion of problems consistently failed. The x-axis displays the mathematical categories: Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, and Precalculus.
### Components/Axes
* **Title:** "Ratios of Consistently Failed Problems Across Categories in MATH-12k" (centered at the top)
* **X-axis Label:** Mathematical Categories (Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, Precalculus)
* **Y-axis Label:** "Zero Ratio (%)" (ranging from 0 to 14, with increments of 2)
* **Legend:** Located in the top-left corner, identifying the three RL models:
* Init RL (Red)
* Base RL (Light Blue)
* Synt RL (Turquoise)
### Detailed Analysis
The chart consists of grouped bar plots for each category, representing the Zero Ratio for each RL model.
* **Algebra:**
* Init RL: Approximately 0.9%
* Base RL: Approximately 0.6%
* Synt RL: Approximately 0.5%
* **Counting & Probability:**
* Init RL: Approximately 5.6%
* Base RL: Approximately 4.2%
* Synt RL: Approximately 3.8%
* **Geometry:**
* Init RL: Approximately 11.9%
* Base RL: Approximately 9.3%
* Synt RL: Approximately 8.8%
* **Intermediate Algebra:**
* Init RL: Approximately 10.8%
* Base RL: Approximately 8.3%
* Synt RL: Approximately 6.7%
* **Number Theory:**
* Init RL: Approximately 3.9%
* Base RL: Approximately 1.9%
* Synt RL: Approximately 1.8%
* **Prealgebra:**
* Init RL: Approximately 1.6%
* Base RL: Approximately 1.3%
* Synt RL: Approximately 0.9%
* **Precalculus:**
* Init RL: Approximately 13.4%
* Base RL: Approximately 10.8%
* Synt RL: Approximately 10.3%
**Trends:**
* For all categories, "Init RL" generally exhibits the highest Zero Ratio, followed by "Base RL", and then "Synt RL".
* The Zero Ratio is particularly high in "Precalculus" and "Geometry" for all models.
* The Zero Ratio is relatively low in "Algebra", "Number Theory", and "Prealgebra" for all models.
### Key Observations
* "Init RL" consistently performs worse (higher Zero Ratio) than the other two models across all categories.
* "Synt RL" generally shows the lowest Zero Ratio, suggesting it is the most effective model in addressing consistently failed problems.
* The largest difference in Zero Ratio between the models is observed in "Intermediate Algebra", where "Init RL" has a significantly higher ratio than "Synt RL".
* The categories "Precalculus" and "Geometry" present the most significant challenges for all models, as indicated by their high Zero Ratios.
### Interpretation
The data suggests that the "Init RL" model struggles more with consistently failed problems across all mathematical categories compared to "Base RL" and "Synt RL". This could be due to the initial training or configuration of the "Init RL" model. The "Synt RL" model appears to be the most robust, consistently achieving the lowest Zero Ratio, indicating its superior ability to address these challenging problems.
The high Zero Ratios in "Precalculus" and "Geometry" highlight these areas as particularly difficult for the models to solve. This could be due to the complexity of the concepts involved or the lack of sufficient training data for these categories. The relatively low Zero Ratios in "Algebra", "Number Theory", and "Prealgebra" suggest that the models are more proficient in these areas.
The differences in performance between the models across different categories could be attributed to the specific training data and algorithms used for each model. Further investigation is needed to understand the underlying reasons for these differences and to improve the performance of the models on the more challenging categories. The data also suggests that the "Synt RL" model is a promising approach for addressing consistently failed problems in mathematical reasoning.