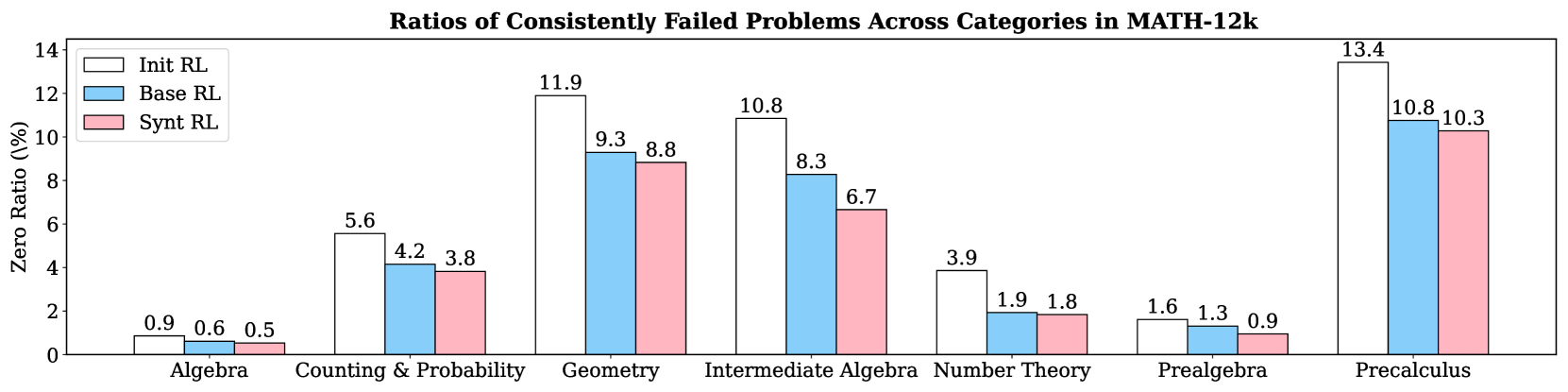
## Grouped Bar Chart: Ratios of Consistently Failed Problems Across Categories in MATH-12k
### Overview
This is a grouped bar chart comparing the performance of three reinforcement learning (RL) methods across seven mathematical problem categories from the MATH-12k dataset. The chart measures the "Zero Ratio (%)", which represents the percentage of problems that were consistently failed. A lower percentage indicates better performance.
### Components/Axes
* **Chart Title:** "Ratios of Consistently Failed Problems Across Categories in MATH-12k"
* **Y-Axis:**
* **Label:** "Zero Ratio (%)"
* **Scale:** Linear scale from 0 to 14, with major tick marks at intervals of 2 (0, 2, 4, 6, 8, 10, 12, 14).
* **X-Axis:**
* **Categories (from left to right):** Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, Precalculus.
* **Legend:** Located in the top-left corner of the chart area.
* **Init RL:** Represented by white bars with a black outline.
* **Base RL:** Represented by light blue bars.
* **Synt RL:** Represented by light pink bars.
### Detailed Analysis
The chart displays the Zero Ratio (%) for each of the three RL methods within each of the seven math categories. The exact values, as labeled on top of each bar, are as follows:
1. **Algebra**
* Init RL: 0.9%
* Base RL: 0.6%
* Synt RL: 0.5%
2. **Counting & Probability**
* Init RL: 5.6%
* Base RL: 4.2%
* Synt RL: 3.8%
3. **Geometry**
* Init RL: 11.9%
* Base RL: 9.3%
* Synt RL: 8.8%
4. **Intermediate Algebra**
* Init RL: 10.8%
* Base RL: 8.3%
* Synt RL: 6.7%
5. **Number Theory**
* Init RL: 3.9%
* Base RL: 1.9%
* Synt RL: 1.8%
6. **Prealgebra**
* Init RL: 1.6%
* Base RL: 1.3%
* Synt RL: 0.9%
7. **Precalculus**
* Init RL: 13.4%
* Base RL: 10.8%
* Synt RL: 10.3%
**Visual Trend Verification:** For every single category, the bar for "Init RL" is the tallest, followed by "Base RL", and then "Synt RL" is the shortest. This creates a consistent descending stair-step pattern within each group from left to right (white -> blue -> pink).
### Key Observations
* **Highest Failure Ratios:** The "Precalculus" category has the highest Zero Ratios for all three methods (Init RL: 13.4%, Base RL: 10.8%, Synt RL: 10.3%), indicating it is the most challenging category for these models.
* **Lowest Failure Ratios:** The "Algebra" category has the lowest Zero Ratios (Init RL: 0.9%, Base RL: 0.6%, Synt RL: 0.5%), suggesting it is the easiest category.
* **Consistent Performance Hierarchy:** The "Synt RL" method consistently achieves the lowest (best) Zero Ratio in every category, followed by "Base RL", with "Init RL" performing the worst.
* **Largest Performance Gap:** The most significant absolute improvement from Init RL to Synt RL is seen in "Intermediate Algebra" (a reduction of 4.1 percentage points, from 10.8% to 6.7%).
* **Smallest Performance Gap:** The smallest absolute improvement is in "Prealgebra" (a reduction of 0.7 percentage points, from 1.6% to 0.9%).
### Interpretation
The data demonstrates a clear and consistent hierarchy in the effectiveness of the three reinforcement learning approaches for solving math problems from the MATH-12k dataset. The "Synt RL" method is universally superior, reducing the rate of consistently failed problems compared to both the "Base RL" and the initial "Init RL" models across all mathematical domains.
The variation in Zero Ratios across categories (from ~0.5% in Algebra to ~13.4% in Precalculus) highlights the differing inherent difficulty of these problem types for the models. The consistent trend suggests that the enhancements in "Synt RL" provide a robust improvement that generalizes well across different mathematical skills, rather than being specialized for a single category. The fact that the relative ordering of the methods never changes strengthens the conclusion that "Synt RL" represents a meaningful advancement over the other two methods tested. The chart effectively argues for the adoption of the "Synt RL" approach to improve model reliability on this benchmark.