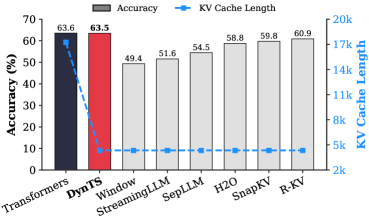
## Dual-Axis Bar & Line Chart: Model Accuracy vs. KV Cache Length
### Overview
This image is a technical comparison chart evaluating eight different models or methods (Transformers, DynTS, Window, StreamingLLM, SepLLM, H2O, SnapKV, R-KV) on two metrics: Accuracy (%) and KV Cache Length. It uses a dual-axis design with bars representing accuracy (left y-axis) and a line representing KV cache length (right y-axis).
### Components/Axes
* **Chart Type:** Combined bar chart and line chart with dual y-axes.
* **X-Axis (Categories):** Lists eight models/methods. From left to right: `Transformers`, `DynTS`, `Window`, `StreamingLLM`, `SepLLM`, `H2O`, `SnapKV`, `R-KV`.
* **Primary Y-Axis (Left):** Labeled `Accuracy (%)`. Scale runs from 0 to 70 in increments of 10.
* **Secondary Y-Axis (Right):** Labeled `KV Cache Length`. Scale runs from 2k to 20k in increments of 3k (2k, 5k, 8k, 11k, 14k, 17k, 20k).
* **Legend:** Positioned at the top center of the chart area.
* A gray rectangle is labeled `Accuracy`.
* A blue line with a circular marker is labeled `KV Cache Length`.
* **Data Series:**
1. **Accuracy (Bars):** The height of each bar corresponds to the accuracy percentage. The first two bars are colored distinctly (dark blue for `Transformers`, red for `DynTS`), while the remaining six bars are gray.
2. **KV Cache Length (Line):** A blue dashed line with circular markers connects data points for each model, corresponding to the right y-axis.
### Detailed Analysis
**Accuracy Data (Bars):**
* `Transformers`: 63.6% (Dark blue bar, tallest)
* `DynTS`: 63.5% (Red bar, nearly equal to Transformers)
* `Window`: 49.4% (Gray bar)
* `StreamingLLM`: 51.6% (Gray bar)
* `SepLLM`: 54.5% (Gray bar)
* `H2O`: 58.8% (Gray bar)
* `SnapKV`: 59.8% (Gray bar)
* `R-KV`: 60.9% (Gray bar)
**KV Cache Length Data (Line - Estimated from visual position against right axis):**
* **Trend Verification:** The line shows a dramatic, steep downward slope from the first point to the second, followed by a nearly flat, low plateau for the remaining six points.
* `Transformers`: ~18k (Highest point, near the 17k-20k range)
* `DynTS`: ~4k (Sharp drop, positioned just above the 2k line)
* `Window`: ~3.5k
* `StreamingLLM`: ~3.5k
* `SepLLM`: ~3.5k
* `H2O`: ~3.5k
* `SnapKV`: ~3.5k
* `R-KV`: ~3.5k
*(Note: Exact values for KV Cache Length are not labeled; these are visual approximations. The line markers for the last six models are all clustered closely together just above the 2k axis line.)*
### Key Observations
1. **Accuracy Cluster:** `Transformers` and `DynTS` form a high-accuracy cluster (~63.5%), significantly outperforming the other six methods, which range from 49.4% to 60.9%.
2. **Efficiency Leap:** There is a massive reduction in KV Cache Length between `Transformers` (~18k) and `DynTS` (~4k), despite nearly identical accuracy.
3. **Performance Plateau:** The six methods from `Window` to `R-KV` show a gradual, incremental improvement in accuracy (from 49.4% to 60.9%) while maintaining a consistently low and similar KV Cache Length (~3.5k).
4. **Visual Emphasis:** The use of distinct colors (dark blue, red) for the first two bars visually highlights them as the primary subjects of comparison against the baseline (gray) methods.
### Interpretation
This chart demonstrates a critical trade-off and advancement in the efficiency of language model inference, specifically regarding the Key-Value (KV) cache, which stores attention keys and values and is a major consumer of memory.
* **The Core Finding:** The `DynTS` method achieves accuracy on par with the standard `Transformers` model while reducing the KV cache memory footprint by approximately 78% (from ~18k to ~4k). This suggests `DynTS` is a highly efficient optimization that preserves performance.
* **The Landscape of Alternatives:** The other six methods (`Window`, `StreamingLLM`, etc.) represent a different point on the efficiency-accuracy curve. They achieve even lower cache usage (~3.5k) but at a notable cost to accuracy (5-14 percentage points lower than `Transformers`/`DynTS`). Their incremental accuracy improvements suggest ongoing refinement within this "low-cache" paradigm.
* **Strategic Implication:** The data positions `DynTS` as a potentially optimal solution for scenarios requiring both high accuracy and memory efficiency. The chart argues that significant cache reduction is possible without the accuracy penalty incurred by the other listed methods. The visualization effectively makes the case for `DynTS` as a superior approach by placing its red bar directly beside the high-accuracy `Transformers` baseline while showing its dramatic drop on the cache-length line.