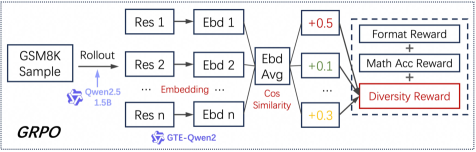
## Process Flow Diagram: GRPO (Group Relative Policy Optimization) Method for Math Problem Solving
### Overview
The image is a technical flowchart illustrating the architecture and data flow of a method labeled "GRPO" (likely Group Relative Policy Optimization). The diagram depicts a reinforcement learning or model training pipeline that starts with a sample from the GSM8K math dataset, processes it through a language model (Qwen2.5 1.5B), generates multiple responses, computes embeddings, and calculates a composite reward signal based on format, mathematical accuracy, and diversity.
### Components/Axes
The diagram is structured as a left-to-right flowchart with the following labeled components and connections:
**1. Input & Initial Processing (Left Region):**
* **Box:** `GSM8K Sample` (Top-left). This is the starting data point.
* **Arrow & Label:** An arrow labeled `Rollout` points from the GSM8K Sample to the next component.
* **Model Icon & Label:** A small icon of a robot head labeled `Qwen2.5 1.5B`. This indicates the language model used for generating responses.
**2. Response Generation & Embedding (Central Region):**
* **Parallel Processing Blocks:** Three vertically stacked, identical structures represent multiple generated responses (Res) and their embeddings (Ebd).
* Top: `Res 1` → `Ebd 1`
* Middle: `Res 2` → `Ebd 2`
* Bottom: `Res n` → `Ebd n`
* **Connecting Text:** The word `Embedding` is written between the `Res` and `Ebd` blocks, clarifying the transformation.
* **Averaging Block:** All `Ebd` blocks feed into a central block labeled `Ebd Avg` (Embedding Average).
* **Similarity Calculation:** An arrow from `Ebd Avg` points to the text `Cos Similarity` (Cosine Similarity).
**3. Reward Calculation (Right Region):**
* **Numerical Values:** Three colored boxes with numerical values are positioned to the right of the central flow:
* Blue box: `+0.5`
* Green box: `+0.1`
* Red box: `+0.3`
* **Reward Components:** These values correspond to three reward types listed in a dashed-border box:
* `Format Reward` (Associated with the blue `+0.5` value)
* `Math Acc Reward` (Mathematical Accuracy Reward, associated with the green `+0.1` value)
* `Diversity Reward` (Associated with the red `+0.3` value and highlighted with a red border).
* **Final Combination:** Plus signs (`+`) connect the three reward components, indicating they are summed to form a total reward signal.
**4. Title/Label:**
* **Text:** `GRPO` is written in the bottom-left corner, serving as the title or acronym for the entire process.
### Detailed Analysis
The process flow is as follows:
1. A single sample is taken from the GSM8K math problem dataset.
2. The Qwen2.5 1.5B model performs a "rollout," generating `n` different responses (`Res 1` to `Res n`) for that sample.
3. Each response is converted into an embedding vector (`Ebd 1` to `Ebd n`).
4. These `n` embeddings are averaged to create a single representative embedding (`Ebd Avg`).
5. A `Cos Similarity` metric is computed, likely comparing the individual response embeddings to the average or to each other to measure diversity.
6. Three distinct reward signals are calculated:
* **Format Reward (+0.5):** Likely rewards responses that adhere to a specific output structure.
* **Math Acc Reward (+0.1):** Rewards responses that are mathematically correct.
* **Diversity Reward (+0.3):** Rewards responses that are different from one another, as measured by the cosine similarity step. This component is visually emphasized with a red border.
7. These three rewards are summed to produce the final training signal for the GRPO method.
### Key Observations
* **Emphasis on Diversity:** The `Diversity Reward` is the only component highlighted with a colored border (red), suggesting it is a critical or novel aspect of the GRPO method being illustrated.
* **Reward Weighting:** The numerical values (+0.5, +0.1, +0.3) imply a weighting scheme where Format is most heavily weighted, followed by Diversity, with Mathematical Accuracy having the lowest direct weight in this depiction. This is an unusual weighting for a math-focused task and may indicate that format and diversity are being used as proxies or regularizers.
* **Multi-Response Generation:** The core mechanism involves generating multiple (`n`) responses per problem, which is central to computing the diversity reward and the averaged embedding.
* **Model Specificity:** The diagram explicitly names the model architecture (`Qwen2.5 1.5B`) and references `GTE-Qwen2` (likely the embedding model), providing concrete technical details.
### Interpretation
This diagram outlines a reinforcement learning from human feedback (RLHF) or similar training strategy tailored for improving mathematical reasoning in language models. The GRPO method appears to address a common failure mode where models might converge on a single, stereotypical way of solving problems.
The key insight is the **explicit optimization for response diversity** alongside correctness and format. By rewarding a set of responses for being different from each other (high variance in embeddings), the method likely encourages the model to explore a wider solution space, discover multiple valid reasoning paths for a given problem, and avoid mode collapse. This could lead to more robust and generalizable problem-solving skills.
The relatively low weight on `Math Acc Reward` (+0.1) is provocative. It suggests that in this specific training phase or formulation, directly rewarding correctness is less important than shaping the *style* (Format) and *exploratory behavior* (Diversity) of the model. The assumption may be that a model which learns to produce diverse, well-formatted attempts will, as a consequence, improve its accuracy through broader exploration. The diagram presents a technical blueprint for implementing this specific inductive bias into a model's training loop.