## Neural Audio Processing Diagram
### Overview
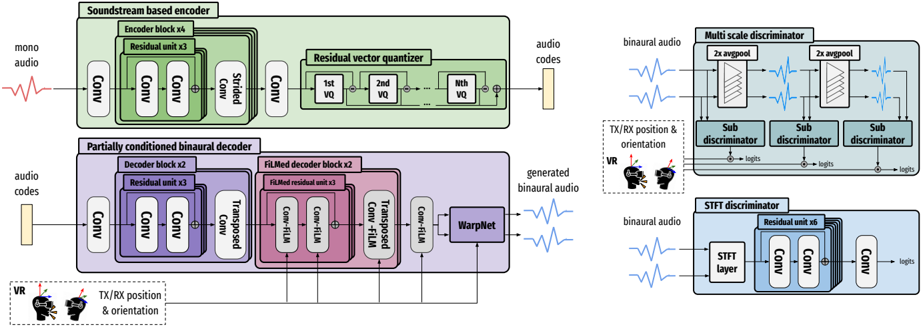
The image presents a block diagram of a neural audio processing system. It includes an encoder, a decoder, and two discriminators. The encoder converts mono audio into audio codes, which are then used by the decoder to generate binaural audio. The discriminators evaluate the generated audio.
### Components/Axes
**Encoder Section (Top-Left):**
* **Title:** Soundstream based encoder
* **Input:** mono audio (represented by a waveform)
* **Blocks:**
* Conv (Convolutional layer)
* Encoder block x4 (containing Residual unit x3)
* Strided Conv (Strided Convolutional layer)
* Residual vector quantizer (containing 1st VQ, 2nd VQ, ..., Nth VQ)
* **Output:** audio codes (represented by a vertical bar)
**Decoder Section (Bottom-Left):**
* **Title:** Partially conditioned binaural decoder
* **Input:** audio codes (represented by a vertical bar)
* **Conditioning Input:** TX/RX position & orientation (with VR headset icon)
* **Blocks:**
* Conv (Convolutional layer)
* Decoder block x2 (containing Residual unit x3)
* Transposed Conv-FiLM (Transposed Convolutional layer with FiLM conditioning)
* FiLMed decoder block x2 (containing FiLMed residual unit x3)
* Conv-FiLM (Convolutional layer with FiLM conditioning)
* WarpNet
* **Output:** generated binaural audio (represented by a waveform)
**Multi-Scale Discriminator (Top-Right):**
* **Title:** Multi scale discriminator
* **Input:** binaural audio (represented by a waveform)
* **Blocks:**
* 2x avgpool (Average pooling layer, repeated twice)
* Sub discriminator (repeated three times)
* **Conditioning Input:** TX/RX position & orientation (with VR headset icon)
* **Output:** logits (from each sub-discriminator)
**STFT Discriminator (Bottom-Right):**
* **Title:** STFT discriminator
* **Input:** binaural audio (represented by a waveform)
* **Blocks:**
* STFT layer (Short-Time Fourier Transform layer)
* Residual unit x6
* Conv (Convolutional layer)
* **Output:** logits
### Detailed Analysis or Content Details
**Encoder:**
1. Mono audio enters the encoder.
2. The audio passes through a convolutional layer (Conv).
3. The audio then goes through four encoder blocks (Encoder block x4), each containing three residual units (Residual unit x3).
4. A strided convolutional layer (Strided Conv) follows.
5. The audio is then processed by a residual vector quantizer (Residual vector quantizer), which contains multiple vector quantization stages (1st VQ, 2nd VQ, ..., Nth VQ).
6. The output of the encoder is audio codes.
**Decoder:**
1. Audio codes enter the decoder.
2. The audio codes pass through a convolutional layer (Conv).
3. The audio codes then go through two decoder blocks (Decoder block x2), each containing three residual units (Residual unit x3).
4. The audio codes are processed by a transposed convolutional layer with FiLM conditioning (Transposed Conv-FiLM).
5. The audio codes then go through two FiLMed decoder blocks (FiLMed decoder block x2), each containing three FiLMed residual units (FiLMed residual unit x3).
6. The audio codes are processed by a convolutional layer with FiLM conditioning (Conv-FiLM).
7. The audio codes are then processed by WarpNet.
8. The output of the decoder is generated binaural audio.
**Multi-Scale Discriminator:**
1. Binaural audio enters the multi-scale discriminator.
2. The audio passes through two average pooling layers (2x avgpool).
3. The audio is then processed by three sub-discriminators (Sub discriminator).
4. The output of each sub-discriminator is logits.
**STFT Discriminator:**
1. Binaural audio enters the STFT discriminator.
2. The audio passes through an STFT layer (STFT layer).
3. The audio is then processed by six residual units (Residual unit x6).
4. The audio is then processed by a convolutional layer (Conv).
5. The output of the discriminator is logits.
### Key Observations
* The system uses a combination of convolutional layers, residual units, and vector quantization to encode and decode audio.
* The decoder is conditioned on the position and orientation of the listener.
* The system uses two discriminators to evaluate the generated audio: a multi-scale discriminator and an STFT discriminator.
### Interpretation
The diagram illustrates a neural audio processing system designed for generating binaural audio from mono audio, potentially for virtual reality (VR) applications. The encoder compresses the mono audio into a set of audio codes, while the decoder reconstructs binaural audio from these codes, taking into account the listener's position and orientation. The use of FiLM conditioning in the decoder suggests that the position and orientation information is used to modulate the audio features. The multi-scale and STFT discriminators likely serve to improve the quality and realism of the generated binaural audio by penalizing artifacts and inconsistencies. The system appears to be designed to create a realistic and immersive audio experience for VR users.