\n
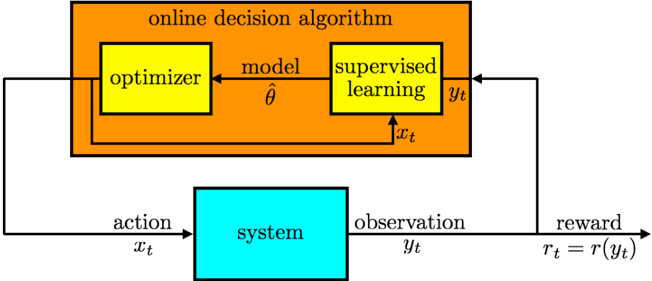
## Diagram: Online Decision Algorithm System
### Overview
The image depicts a diagram illustrating an online decision algorithm interacting with a "system". The algorithm consists of an optimizer and a supervised learning model, and the interaction involves actions, observations, and rewards. The diagram shows the flow of information between the algorithm and the system.
### Components/Axes
The diagram consists of two main blocks:
1. **Online Decision Algorithm:** A large orange rectangle labeled "online decision algorithm". This block contains two smaller blocks: "optimizer" and "supervised learning".
2. **System:** A turquoise rectangle labeled "system".
The following labels are present, indicating data flow:
* **x<sub>t</sub>**: Action input to the system.
* **y<sub>t</sub>**: Observation output from the system.
* **r<sub>t</sub> = r(y<sub>t</sub>)**: Reward calculated from the observation.
* **â** : Model parameter estimate.
* **x<sub>t</sub>**: Action input to the supervised learning model.
### Detailed Analysis or Content Details
The diagram shows the following flow:
1. The "online decision algorithm" receives an observation (y<sub>t</sub>) from the "system".
2. The observation (y<sub>t</sub>) is fed into the "supervised learning" block.
3. The "supervised learning" block outputs a model parameter estimate (â) to the "optimizer".
4. The "optimizer" adjusts the model based on the observation and outputs an action (x<sub>t</sub>) to the "system".
5. The "system" receives the action (x<sub>t</sub>) and produces an observation (y<sub>t</sub>) and a reward (r<sub>t</sub>).
6. The reward (r<sub>t</sub>) is fed back into the "online decision algorithm" to influence future actions.
The reward is defined as r<sub>t</sub> = r(y<sub>t</sub>), indicating that the reward is a function of the observation.
### Key Observations
The diagram illustrates a closed-loop system where the algorithm learns from the environment (the "system") through trial and error. The "supervised learning" component suggests that the algorithm uses observed data to improve its model, while the "optimizer" component suggests that the algorithm adjusts its parameters to maximize the reward.
### Interpretation
This diagram represents a reinforcement learning framework. The "online decision algorithm" acts as an agent that interacts with an environment (the "system"). The agent takes actions (x<sub>t</sub>), receives observations (y<sub>t</sub>) and rewards (r<sub>t</sub>), and learns to optimize its actions to maximize the cumulative reward. The use of "supervised learning" within the algorithm suggests a model-based reinforcement learning approach, where the agent learns a model of the environment and uses this model to predict future outcomes. The feedback loop between the algorithm and the system is crucial for the learning process, as it allows the algorithm to adapt to the environment and improve its performance over time. The equation r<sub>t</sub> = r(y<sub>t</sub>) highlights that the reward is directly tied to the state of the environment as observed by the agent. This is a common setup in reinforcement learning where the reward function defines the goal of the agent.