## Diagram: Hybrid Probabilistic-Classical Computer System
### Overview
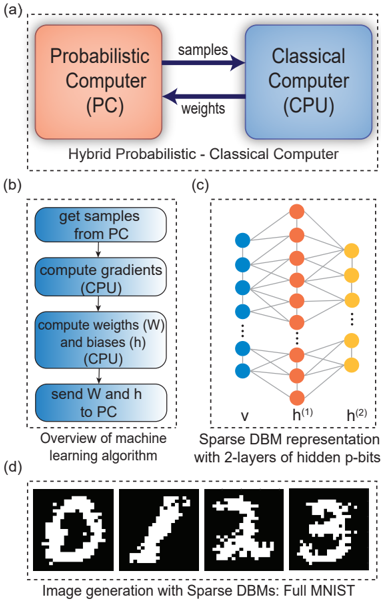
The image presents a system diagram of a hybrid probabilistic-classical computer, a machine learning algorithm overview, a sparse Deep Boltzmann Machine (DBM) representation, and image generation results using sparse DBMs. It is divided into four sub-figures labeled (a), (b), (c), and (d).
### Components/Axes
* **(a) Hybrid Probabilistic - Classical Computer:**
* Two rectangular blocks represent the "Probabilistic Computer (PC)" (colored orange) and the "Classical Computer (CPU)" (colored blue).
* Arrows indicate data flow: "samples" from PC to CPU, and "weights" from CPU to PC.
* **(b) Overview of machine learning algorithm:**
* A flowchart with four rounded rectangles, each representing a step in the algorithm.
* "get samples from PC"
* "compute gradients (CPU)"
* "compute weights (W) and biases (h) (CPU)"
* "send W and h to PC"
* **(c) Sparse DBM representation with 2-layers of hidden p-bits:**
* A neural network diagram with three layers of nodes.
* Input layer 'v' (blue nodes).
* First hidden layer 'h^(1)' (orange nodes).
* Second hidden layer 'h^(2)' (yellow nodes).
* Lines connect nodes between layers, representing connections/weights.
* **(d) Image generation with Sparse DBMs: Full MNIST:**
* Four black and white images, presumably generated digits from the MNIST dataset. The digits appear to be 0, 1, 2, and 3.
### Detailed Analysis
* **(a)** The Probabilistic Computer (PC) and Classical Computer (CPU) exchange data. The PC sends samples to the CPU, and the CPU sends weights back to the PC.
* **(b)** The machine learning algorithm involves getting samples from the PC, computing gradients and weights/biases using the CPU, and sending the weights/biases back to the PC.
* **(c)** The Sparse DBM has an input layer (v) and two hidden layers (h^(1) and h^(2)). The connections between layers suggest a feedforward network.
* **(d)** The generated images are pixelated representations of digits, indicating the DBM's ability to generate images.
### Key Observations
* The system combines probabilistic and classical computing elements.
* The machine learning algorithm is iterative, involving data exchange between the PC and CPU.
* The DBM architecture has two hidden layers.
* The generated images are recognizable as digits, demonstrating the model's learning capability.
### Interpretation
The diagram illustrates a hybrid computing system where a probabilistic computer and a classical computer work together to perform machine learning tasks. The probabilistic computer likely provides samples for training, while the classical computer handles the computationally intensive tasks of gradient calculation and weight updates. The sparse DBM is used for image generation, and the results show that the model can learn to generate recognizable digits. The system leverages the strengths of both probabilistic and classical computing to achieve its goals.