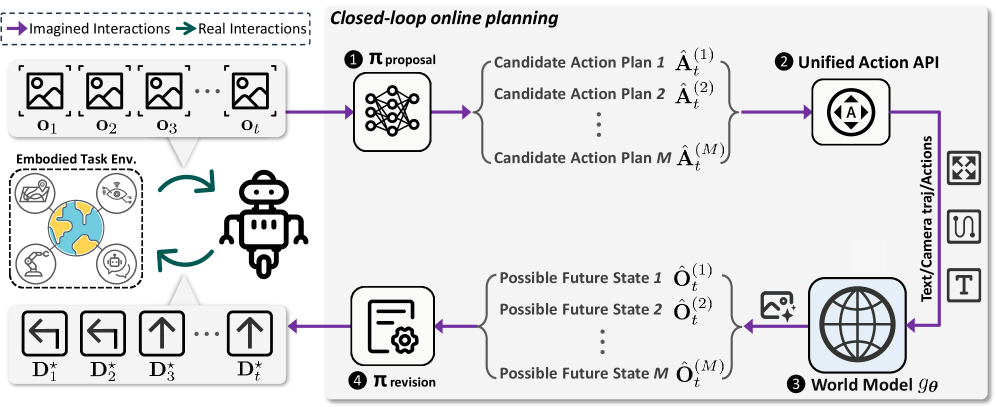
## Diagram: Closed-loop Online Planning System
### Overview
This image is a technical system diagram illustrating a "Closed-loop online planning" framework for an embodied robotic agent. The diagram depicts a cyclical process where the agent uses imagined interactions to propose and revise action plans before executing them in a real environment. The flow is indicated by colored arrows, with a legend differentiating between imagined (purple) and real (teal) interactions.
### Components/Axes
**Legend (Top-Left):**
* **Purple Arrow:** Imagined Interactions
* **Teal Arrow:** Real Interactions
**Main Diagram Components (Spatially arranged from left to right, then looping back):**
1. **Embodied Task Env. (Left):** A dashed box containing icons representing the agent's environment. Icons include a globe, a robotic arm, a person at a desk, and a chat bubble.
2. **Observation Sequence (Top-Left):** A series of image icons labeled `O₁`, `O₂`, `O₃`, ..., `Oₜ`. A purple arrow points from this sequence into the planning system.
3. **Robot Icon (Center-Left):** A simple robot figure. Teal arrows point from the "Embodied Task Env." to the robot and from the robot back to the environment, indicating real interaction.
4. **Action Sequence (Bottom-Left):** A series of directional arrow icons labeled `D*₁`, `D*₂`, `D*₃`, ..., `D*ₜ`. A purple arrow points from the planning system to this sequence.
5. **Planning System (Right, within a large rounded rectangle):** This is the core processing unit, containing four numbered modules:
* **① π proposal:** Represented by a neural network icon. It receives observations (`Oₜ`) and outputs multiple candidate action plans.
* **Candidate Action Plans:** Listed as `Âₜ⁽¹⁾`, `Âₜ⁽²⁾`, ..., `Âₜ⁽ᴹ⁾`.
* **② Unified Action API:** Represented by an icon with an 'A' inside a circle and arrows. It receives the candidate plans.
* **③ World Model gθ:** Represented by a globe icon. It receives text/camera trajectories/actions from the API and outputs possible future states.
* **Possible Future States:** Listed as `Ôₜ⁽¹⁾`, `Ôₜ⁽²⁾`, ..., `Ôₜ⁽ᴹ⁾`.
* **④ π revision:** Represented by a document/gear icon. It receives the possible future states and outputs the final chosen action sequence (`D*ₜ`).
6. **Output Icons (Far Right):** Three small icons vertically aligned: a camera, a path/trajectory symbol, and the letter 'T'. These are connected to the World Model via a purple arrow labeled "Text/Camera traj/Actions".
### Detailed Analysis
**Flow and Relationships:**
The process begins with the agent observing the environment (`O₁...Oₜ`). These observations are fed (purple arrow) into the **π proposal** module (1), which generates `M` candidate action plans (`Âₜ⁽¹⁾...Âₜ⁽ᴹ⁾`). These plans are processed by the **Unified Action API** (2), which interfaces with the **World Model gθ** (3). The World Model simulates the outcomes of each candidate plan, producing `M` corresponding **Possible Future States** (`Ôₜ⁽¹⁾...Ôₜ⁽ᴹ⁾`). These simulated outcomes are evaluated by the **π revision** module (4), which selects the optimal action sequence (`D*₁...D*ₜ`). This chosen sequence is then executed in the real **Embodied Task Env.** via the robot (teal arrows), closing the loop. The cycle repeats with new observations.
**Text Transcription:**
All text in the diagram is in English. Key transcribed text includes:
* Title: "Closed-loop online planning"
* Legend: "Imagined Interactions", "Real Interactions"
* Module Labels: "① π proposal", "② Unified Action API", "③ World Model gθ", "④ π revision"
* Data Labels: `O₁`, `O₂`, `O₃`, `Oₜ`; `Âₜ⁽¹⁾`, `Âₜ⁽²⁾`, `Âₜ⁽ᴹ⁾`; `Ôₜ⁽¹⁾`, `Ôₜ⁽²⁾`, `Ôₜ⁽ᴹ⁾`; `D*₁`, `D*₂`, `D*₃`, `D*ₜ`
* Descriptive Text: "Embodied Task Env.", "Candidate Action Plan 1", "Candidate Action Plan 2", "Candidate Action Plan M", "Possible Future State 1", "Possible Future State 2", "Possible Future State M", "Text/Camera traj/Actions"
### Key Observations
1. **Dual Interaction Loops:** The system explicitly separates internal, simulated planning (purple "Imagined Interactions") from external, physical execution (teal "Real Interactions").
2. **Parallel Hypothesis Testing:** The core of the planning system is parallelized. Both the action proposal (`Âₜ⁽ᴹ⁾`) and the world model's state prediction (`Ôₜ⁽ᴹ⁾`) operate over `M` candidates simultaneously, suggesting a Monte Carlo or beam-search-like approach to planning.
3. **Model-Based Reinforcement Learning Structure:** The architecture follows a classic model-based RL pattern: an actor (π proposal) proposes actions, a world model (gθ) predicts outcomes, and a critic/revision module (π revision) evaluates them to select the best action.
4. **Symbolic and Perceptual Integration:** The World Model takes "Text/Camera traj/Actions" as input, indicating it integrates both symbolic (text) and perceptual (camera) data to make its predictions.
### Interpretation
This diagram represents a sophisticated architecture for an intelligent agent that "thinks before it acts." The key innovation is the **closed-loop online planning** mechanism. Instead of reacting reflexively, the agent uses its internal **World Model (gθ)**—a learned simulator of reality—to imagine the consequences of multiple potential action plans. The **π revision** module then acts as a decision-maker, choosing the plan predicted to lead to the most desirable future state.
The system's power lies in this ability to conduct risk-free, rapid internal simulations. It allows the robot to explore various strategies in its "mind" before committing to a physical action, which is crucial for complex, irreversible, or safety-critical tasks in the real world. The separation of the "Unified Action API" suggests a modular design where different planning strategies or action representations can be plugged in. The entire loop enables continuous adaptation: the agent acts, observes the real outcome, updates its understanding, and refines its future plans accordingly. This is a foundational paradigm for creating autonomous systems that can operate effectively in dynamic and uncertain environments.