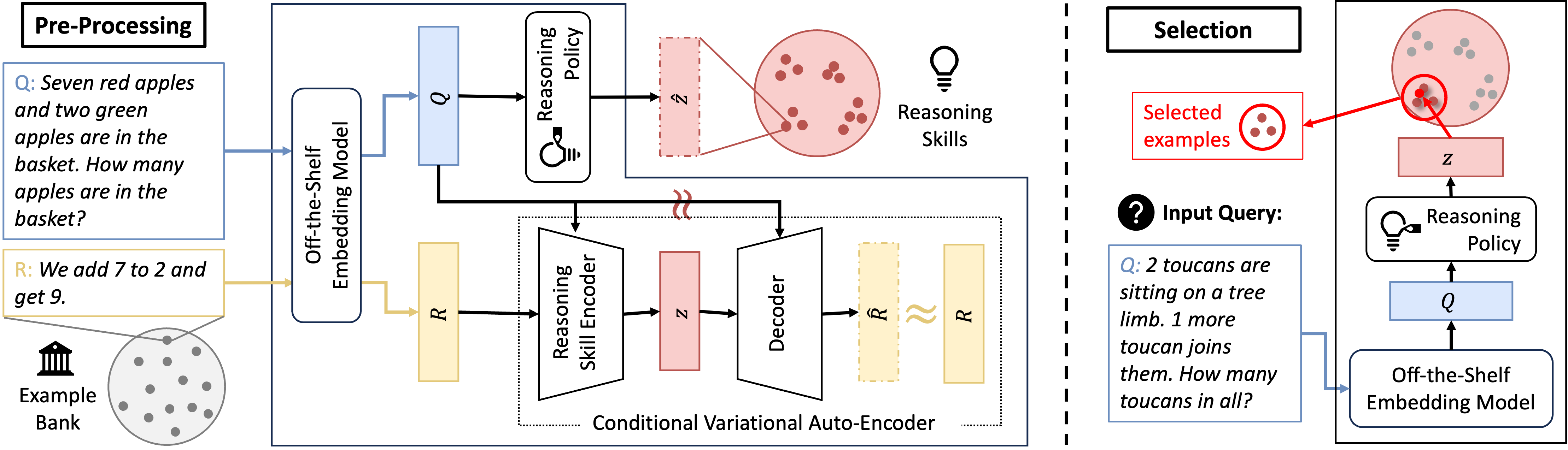
## Diagram: Reasoning Skills Selection Process
### Overview
The image presents a diagram illustrating a reasoning skills selection process. It is divided into two main sections: "Pre-Processing" on the left and "Selection" on the right, separated by a dashed vertical line. The diagram shows how an input question is processed, how relevant examples are retrieved, and how a reasoning policy is applied to select the appropriate reasoning skills.
### Components/Axes
**Pre-Processing (Left Side):**
* **Title:** "Pre-Processing" in a black box at the top-left.
* **Question (Q):** A blue box containing the question: "Q: Seven red apples and two green apples are in the basket. How many apples are in the basket?"
* **Response (R):** A yellow box containing the response: "R: We add 7 to 2 and get 9."
* **Example Bank:** A bank icon with a circle containing scattered dots labeled "Example Bank" below the response.
* **Off-the-Shelf Embedding Model:** A rounded rectangle labeled "Off-the-Shelf Embedding Model."
* **Reasoning Policy:** A lightbulb icon with the label "Reasoning Policy."
* **Reasoning Skills:** A red circle containing scattered dots with the label "Reasoning Skills."
* **Conditional Variational Auto-Encoder:** A dotted rectangle containing "Reasoning Skill Encoder," "Decoder," and a latent variable "z."
**Selection (Right Side):**
* **Title:** "Selection" in a black box at the top-right.
* **Input Query:** A question mark icon with the label "Input Query:".
* **Question (Q):** A blue box containing the question: "Q: 2 toucans are sitting on a tree limb. 1 more toucan joins them. How many toucans in all?"
* **Off-the-Shelf Embedding Model:** A rounded rectangle labeled "Off-the-Shelf Embedding Model."
* **Reasoning Policy:** A lightbulb icon with the label "Reasoning Policy."
* **Latent Variable (z):** A red box labeled "z."
* **Selected Examples:** A red box labeled "Selected examples" pointing to a red circle containing a few dots.
### Detailed Analysis or ### Content Details
**Pre-Processing Flow:**
1. The question (Q) and response (R) from the "Pre-Processing" section are fed into the "Off-the-Shelf Embedding Model."
2. The output of the embedding model for Q goes to a blue box labeled "Q" and then to the "Reasoning Policy" (lightbulb icon).
3. The output of the embedding model for R goes to a yellow box labeled "R" and then to the "Reasoning Skill Encoder" within the "Conditional Variational Auto-Encoder."
4. The "Reasoning Skill Encoder" encodes the information into a latent variable "z" (red box), which is then passed to the "Decoder."
5. The "Decoder" attempts to reconstruct the response, resulting in "R-hat" (yellow dashed box), which is compared to the original "R" (yellow box).
6. The "Reasoning Policy" also influences the selection of "Reasoning Skills" (red circle with dots).
**Selection Flow:**
1. The "Input Query" (question about toucans) is fed into the "Off-the-Shelf Embedding Model."
2. The output of the embedding model goes to a blue box labeled "Q" and then to the "Reasoning Policy" (lightbulb icon).
3. The "Reasoning Policy" selects a latent variable "z" (red box) and also selects "Selected examples" (red circle with a few dots) from a larger set of examples (red circle with many dots).
### Key Observations
* The diagram illustrates a process for selecting reasoning skills based on input questions and examples.
* The "Conditional Variational Auto-Encoder" is used to learn a latent representation of reasoning skills.
* The "Reasoning Policy" plays a crucial role in selecting both the latent variable "z" and the relevant examples.
* The "Pre-Processing" section uses a question about apples, while the "Selection" section uses a question about toucans, suggesting the system can handle different types of reasoning problems.
### Interpretation
The diagram presents a model for automated reasoning skill selection. The "Pre-Processing" section likely represents a training phase where the model learns to associate questions with appropriate reasoning strategies. The "Selection" section demonstrates how the trained model applies this knowledge to new, unseen questions. The use of a "Conditional Variational Auto-Encoder" suggests that the model aims to learn a compressed and structured representation of reasoning skills, allowing for efficient selection and application. The "Reasoning Policy" acts as a central control mechanism, guiding the selection process based on the input question and the learned latent representations. The selection of "Selected examples" indicates that the model also leverages relevant examples to improve its reasoning performance.