## Bar Chart: Accuracy of Embedding Models
### Overview
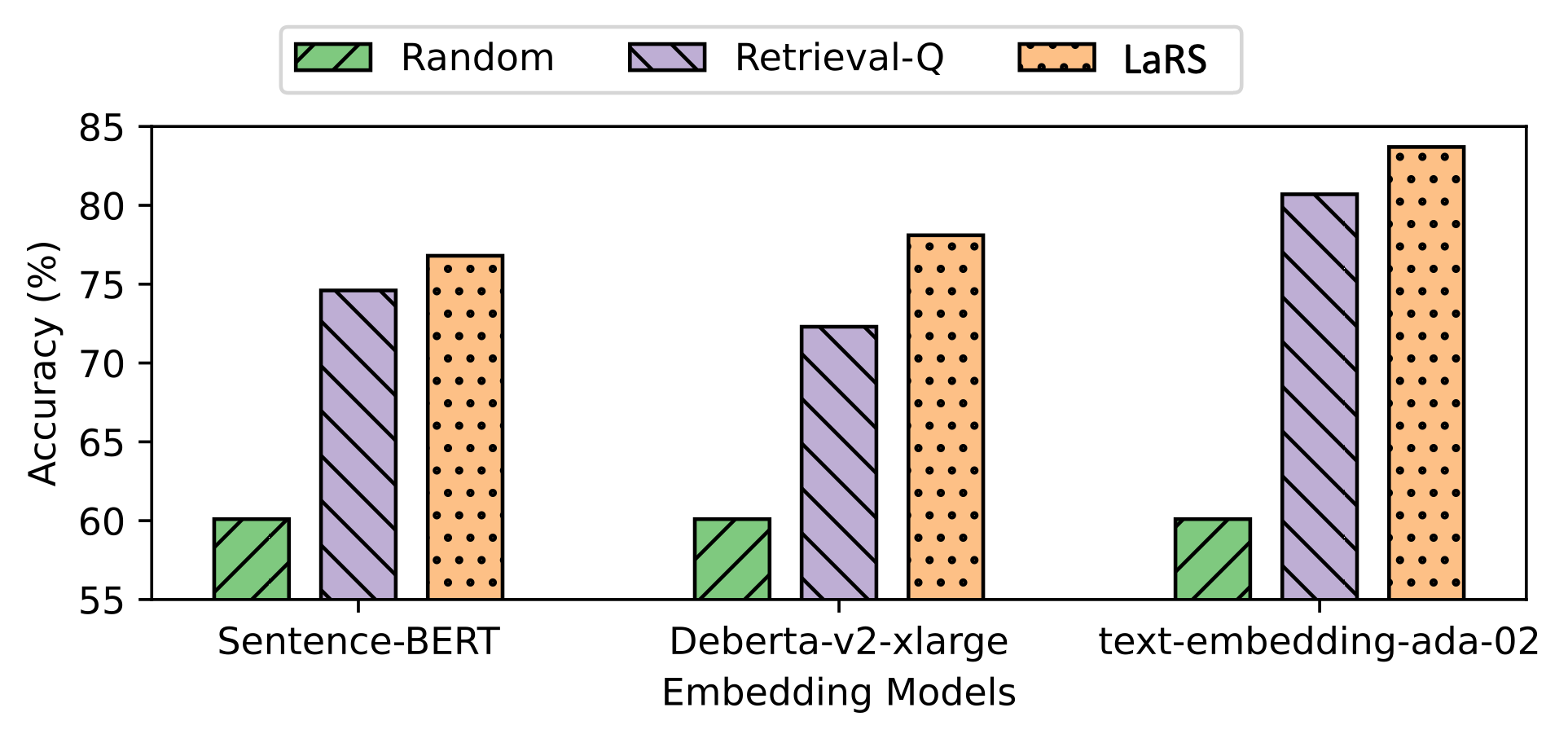
The image is a bar chart comparing the accuracy of three embedding models (Sentence-BERT, Deberta-v2-xlarge, and text-embedding-ada-02) using three different methods: Random, Retrieval-Q, and LaRS. The chart displays accuracy in percentage on the y-axis and the embedding models on the x-axis.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** "Embedding Models" with categories: Sentence-BERT, Deberta-v2-xlarge, text-embedding-ada-02.
* **Y-axis:** "Accuracy (%)" with a scale from 55 to 85, incrementing by 5.
* **Legend:** Located at the top of the chart.
* Green: Random
* Lavender with diagonal lines: Retrieval-Q
* Peach with dots: LaRS
### Detailed Analysis
Here's a breakdown of the accuracy for each embedding model and method:
* **Sentence-BERT:**
* Random: Approximately 60%
* Retrieval-Q: Approximately 74.5%
* LaRS: Approximately 76.5%
* **Deberta-v2-xlarge:**
* Random: Approximately 60%
* Retrieval-Q: Approximately 72%
* LaRS: Approximately 78%
* **text-embedding-ada-02:**
* Random: Approximately 60%
* Retrieval-Q: Approximately 80.5%
* LaRS: Approximately 84%
### Key Observations
* For all three embedding models, the "Random" method consistently yields the lowest accuracy, hovering around 60%.
* "LaRS" generally provides the highest accuracy among the three methods for each embedding model.
* "text-embedding-ada-02" achieves the highest accuracy overall, particularly with the "LaRS" method.
### Interpretation
The chart demonstrates that the choice of method significantly impacts the accuracy of embedding models. The "Random" method serves as a baseline, showing the inherent accuracy without specific retrieval or learning strategies. "Retrieval-Q" and "LaRS" improve upon this baseline, with "LaRS" generally outperforming "Retrieval-Q." The "text-embedding-ada-02" model, when combined with the "LaRS" method, appears to be the most effective configuration for achieving high accuracy. The consistent low performance of the "Random" method suggests that targeted retrieval and learning strategies are crucial for maximizing the potential of these embedding models.