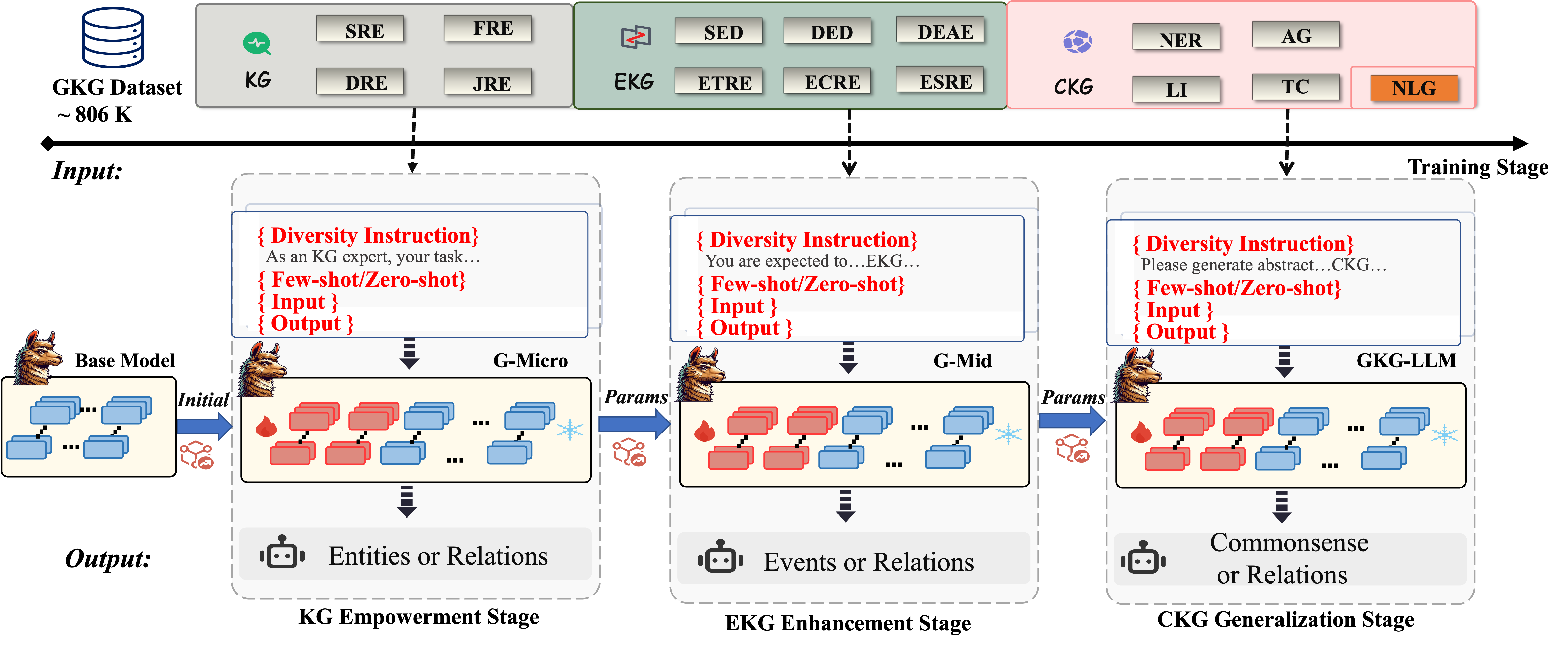
## Diagram: Knowledge Graph Enhanced Large Language Model Training Pipeline
### Overview
This diagram illustrates a three-stage pipeline for training a large language model (LLM) enhanced with knowledge graphs (KG). The pipeline begins with a KG dataset, progresses through micro and mid-level training stages (G-Micro, G-Mid), and culminates in a KG-LLM stage. Each stage involves inputting data, processing it through a model, and generating an output. The diagram emphasizes the use of "Diversity Instruction" at each stage.
### Components/Axes
The diagram is structured into three main columns representing the three training stages: KG Empowerment, EKG Enhancement, and CKG Generalization. Each stage has an "Input" section, a processing block (G-Micro, G-Mid, GK-LLM), and an "Output" section. A "Base Model" is shown at the bottom, feeding into the first stage. A "GKG Dataset ~806K" cylinder is at the top-left, representing the initial data source.
**Input Stage Labels (Top Row):**
* **KG:** SRE, FRE, DRE, JRE
* **EKG:** SED, DED, DEAE, ETRE, ECRE, ESIE
* **CKG:** NER, AG, LI, TC, NLG
**Stage Titles:**
* KG Empowerment Stage
* EKG Enhancement Stage
* CKG Generalization Stage
**Diversity Instruction Boxes:**
* "As an KG expert, your task..." (KG Empowerment)
* "You are expected to...EKG..." (EKG Enhancement)
* "Please generate abstract...CKG..." (CKG Generalization)
**Model Blocks:**
* G-Micro
* G-Mid
* GK-LLM
**Output Icons:**
* Entities or Relations (KG Empowerment)
* Events or Relations (EKG Enhancement)
* Commonsense or Relations (CKG Generalization)
### Detailed Analysis or Content Details
The diagram shows a flow of information from the GKG Dataset (~806K) to the Base Model, then through the three stages.
**Stage 1: KG Empowerment**
* **Input:** The KG input consists of four categories: SRE, FRE, DRE, and JRE.
* **Processing:** The input is fed into the G-Micro model. The model is shown as a series of interconnected boxes, with arrows indicating data flow. "Params" are passed from the G-Micro model to the next stage.
* **Output:** The output is represented by an icon of entities or relations.
**Stage 2: EKG Enhancement**
* **Input:** The EKG input consists of six categories: SED, DED, DEAE, ETRE, ECRE, and ESIE.
* **Processing:** The input is fed into the G-Mid model, which is similarly structured as G-Micro. "Params" are passed from the G-Mid model to the next stage.
* **Output:** The output is represented by an icon of events or relations.
**Stage 3: CKG Generalization**
* **Input:** The CKG input consists of five categories: NER, AG, LI, TC, and NLG.
* **Processing:** The input is fed into the GK-LLM model, which is similarly structured as G-Micro and G-Mid.
* **Output:** The output is represented by an icon of commonsense or relations.
The "Training Stage" label is positioned at the top-right, indicating the overall context of the diagram. The "Input" label is positioned at the top-left, and the "Output" label is positioned at the bottom-center. The "Diversity Instruction" boxes are placed above each model block, indicating their role in guiding the training process.
### Key Observations
The diagram highlights a sequential training process, where each stage builds upon the previous one. The use of "Diversity Instruction" suggests a focus on generating varied and robust outputs. The increasing complexity of the input categories (4 in KG, 6 in EKG, 5 in CKG) might indicate a growing need for more nuanced data as the model progresses. The outputs shift from basic entities/relations to more complex events/relations and finally to commonsense/relations, suggesting a progression in the model's understanding capabilities.
### Interpretation
This diagram depicts a pipeline for enhancing a large language model with knowledge graphs. The three stages – KG Empowerment, EKG Enhancement, and CKG Generalization – represent a phased approach to integrating knowledge into the model. The initial stage focuses on establishing a foundation of entities and relations, the second stage refines this with event-based knowledge, and the final stage aims to instill commonsense reasoning. The "Diversity Instruction" component suggests a deliberate effort to avoid biases and promote generalization. The diagram implies that the model starts with a "Base Model" and iteratively improves its performance through the three stages, leveraging the knowledge graphs and the specified training instructions. The use of "Params" passing between stages suggests a form of transfer learning or fine-tuning. The diagram is a high-level overview and doesn't provide specific details about the model architectures or training algorithms used.