TECHNICAL ASSET FINGERPRINT
901c2ea05912e9d0549da83a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
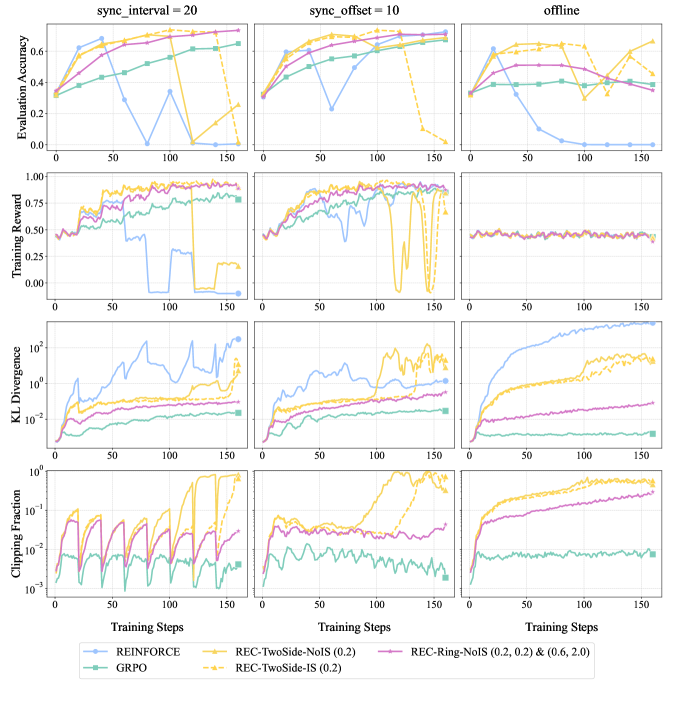
## Multi-Panel Line Chart: Training Metrics Comparison Across Synchronization Settings
### Overview
The image is a 4x3 grid of line charts comparing the performance of six different reinforcement learning or policy optimization methods across three distinct training synchronization configurations. The charts track four key metrics over 150 training steps. The overall purpose is to visualize and compare the stability, performance, and optimization behavior of the methods under different synchronization regimes.
### Components/Axes
* **Column Headers (Synchronization Settings):**
* Left Column: `sync_interval = 20`
* Middle Column: `sync_offset = 10`
* Right Column: `offline`
* **Row Headers (Metrics):**
* Top Row: `Evaluation Accuracy` (Y-axis scale: 0.0 to ~0.7)
* Second Row: `Training Reward` (Y-axis scale: 0.00 to 1.00)
* Third Row: `KL Divergence` (Y-axis scale: logarithmic, from 10^-3 to 10^1)
* Bottom Row: `Clipping Fraction` (Y-axis scale: logarithmic, from 10^-3 to 10^0)
* **Common X-Axis:** `Training Steps` (Linear scale, marked at 0, 50, 100, 150).
* **Legend (Bottom Center):** Contains six entries, each with a unique color and marker:
1. `REINFORCE` - Light blue line with circle markers.
2. `GRPO` - Teal/green line with square markers.
3. `REC-TwoSide-NoIS (0.2)` - Yellow line with upward-pointing triangle markers.
4. `REC-TwoSide-IS (0.2)` - Yellow dashed line with downward-pointing triangle markers.
5. `REC-Ring-NoIS (0.2, 0.2) & (0.6, 2.0)` - Purple line with plus sign markers.
6. `REC-Ring-NoIS (0.2, 0.2)` - Pink/magenta line with 'x' markers.
### Detailed Analysis
**Column 1: `sync_interval = 20`**
* **Evaluation Accuracy:** Most methods (GRPO, REC variants) show a steady increase from ~0.3 to between 0.6-0.7. `REINFORCE` (blue) increases initially but crashes to near 0.0 after step 50. `REC-TwoSide-NoIS` (yellow triangle) also crashes after step 100.
* **Training Reward:** Mirrors accuracy trends. GRPO and REC variants rise to ~0.8-0.9. `REINFORCE` crashes to 0.0 after step 50. `REC-TwoSide-NoIS` crashes after step 100.
* **KL Divergence:** `REINFORCE` shows the highest and most volatile divergence, peaking above 10^1. Other methods remain lower, with GRPO and the pink `REC-Ring-NoIS` being the most stable (lowest divergence, ~10^-2 to 10^-1).
* **Clipping Fraction:** Shows periodic, sharp oscillations for several methods (notably the pink and purple `REC-Ring-NoIS` variants), suggesting regular policy updates hitting clipping boundaries. `REINFORCE` and `GRPO` have lower, more stable clipping fractions.
**Column 2: `sync_offset = 10`**
* **Evaluation Accuracy:** Similar initial rise for most. `REINFORCE` crashes early (around step 50). `REC-TwoSide-NoIS` (yellow triangle) maintains performance longer but crashes after step 125.
* **Training Reward:** `REINFORCE` crashes to 0.0. `REC-TwoSide-NoIS` shows extreme volatility, dropping to 0.0 multiple times before a final crash. Other methods remain high and stable.
* **KL Divergence:** `REINFORCE` again shows high divergence. `REC-TwoSide-NoIS` shows a late, sharp increase in divergence coinciding with its performance crash.
* **Clipping Fraction:** `REC-TwoSide-NoIS` shows a massive spike to near 1.0 (10^0) after step 125, indicating almost all updates were clipped. Other methods show moderate, stable clipping.
**Column 3: `offline`**
* **Evaluation Accuracy:** `REINFORCE` performance decays steadily to near 0.0. `REC-TwoSide-NoIS` (yellow triangle) is highly volatile, oscillating between ~0.2 and 0.7. The other four methods maintain stable, high accuracy (~0.6-0.7).
* **Training Reward:** `REINFORCE` and the two `REC-TwoSide` methods show flat or declining rewards (~0.4-0.5). The GRPO and `REC-Ring` methods maintain stable, high rewards (~0.8-0.9).
* **KL Divergence:** `REINFORCE` divergence grows monotonically and very high (approaching 10^2). `REC-TwoSide-NoIS` also shows high, growing divergence. The other methods maintain low, stable divergence.
* **Clipping Fraction:** `REC-TwoSide-NoIS` and the purple `REC-Ring-NoIS` show a steady increase in clipping fraction over time, ending near 1.0. `GRPO` remains very low and stable.
### Key Observations
1. **Method Stability Hierarchy:** `GRPO` (teal) and the `REC-Ring-NoIS` variants (purple/pink) are consistently the most stable across all metrics and synchronization settings. `REINFORCE` (blue) is consistently the least stable, often crashing completely.
2. **Sensitivity of REC-TwoSide:** The `REC-TwoSide-NoIS` method (yellow triangle) is highly sensitive to the synchronization setting. It performs well initially in synchronized settings but exhibits catastrophic forgetting or instability later, and is highly volatile in the offline setting.
3. **KL Divergence as a Failure Indicator:** High and growing KL Divergence (especially for `REINFORCE` and `REC-TwoSide-NoIS` in offline mode) strongly correlates with performance collapse (drops in Accuracy and Reward).
4. **Offline Setting is Challenging:** The `offline` configuration appears most difficult, causing performance decay in `REINFORCE` and severe volatility in `REC-TwoSide-NoIS`, while other methods remain robust.
5. **Clipping Correlates with Instability:** Spikes in Clipping Fraction (e.g., `REC-TwoSide-NoIS` in `sync_offset=10`) immediately precede or coincide with performance crashes, suggesting optimization difficulties.
### Interpretation
This data demonstrates a comparative analysis of policy optimization algorithms, likely in a reinforcement learning from human feedback (RLHF) or similar context. The core finding is that **synchronization strategy critically impacts algorithm stability and performance**.
* **Synchronized Training (`sync_interval`, `sync_offset`)** provides a stabilizing effect for most methods, but can delay the onset of instability for sensitive algorithms like `REC-TwoSide-NoIS`, leading to a sudden, catastrophic collapse after many steps of apparent success.
* **Offline Training** removes this stabilizing buffer, exposing inherent weaknesses. Algorithms that rely on frequent, on-policy updates (`REINFORCE`) fail completely. Algorithms with potentially high variance (`REC-TwoSide`) become unusably volatile. The success of `GRPO` and `REC-Ring` variants suggests they have inherent mechanisms (perhaps related to their gradient estimation or trust region methods) that make them robust to distribution shift and stale data, which are key challenges in offline optimization.
* The **strong correlation between rising KL Divergence and falling performance** underscores the importance of monitoring this metric as a health check for the training process. It indicates the policy is drifting too far from its reference model, leading to collapse.
* The **Clipping Fraction** acts as a diagnostic for optimization health. A value approaching 1.0 means the optimizer is constantly fighting against its own update constraints, a sign of impending failure.
In essence, the charts argue for the use of robust algorithms (`GRPO`, `REC-Ring`) and careful consideration of synchronization schemes, especially when moving towards offline or large-interval update paradigms, to ensure stable and reliable training.
DECODING INTELLIGENCE...