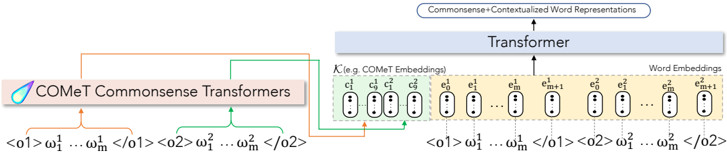
## Diagram: COMeT Commonsense Transformers Architecture
### Overview
The diagram illustrates a technical architecture for generating **Commonsense+Contextualized Word Representations** using COMeT (Conceptual Commonsense Transformers). It depicts a multi-stage pipeline involving two COMeT Commonsense Transformers, a central Transformer, and word embedding outputs. The flow of data is represented through color-coded arrows (orange, green, blue) connecting components.
---
### Components/Axes
1. **COMeT Commonsense Transformers**
- **Inputs**:
- `<o1>` with parameters `ω₁ ... ωₘ`
- `<o2>` with parameters `ω₁ ... ωₘ`
- **Outputs**:
- `c₁, c₉, c₁, c₉` (labeled as "COMeT Embeddings")
2. **Transformer**
- **Inputs**:
- `e₀, e₁, ..., eₘ, eₘ₊₁` (word embeddings)
- **Outputs**:
- `e₀, e₁, ..., eₘ, eₘ₊₁` (contextualized word embeddings)
3. **Word Embeddings**
- Final output: `e₀, e₁, ..., eₘ, eₘ₊₁`
**Legend**:
- **Orange arrows**: Data flow from COMeT Transformers to the central Transformer.
- **Green arrows**: Internal connections between COMeT outputs.
- **Blue arrows**: Data flow from the Transformer to word embeddings.
---
### Detailed Analysis
- **COMeT Transformers**:
- Processes two input sequences (`<o1>` and `<o2>`) with shared parameter sets (`ω₁ ... ωₘ`).
- Generates embeddings `c₁, c₉` (possibly representing concept or contextual features).
- **Transformer**:
- Integrates COMeT embeddings (`c₁, c₉`) with word embeddings (`e₀ ... eₘ₊₁`).
- Produces contextualized word representations (`e₀ ... eₘ₊₁`).
- **Embedding Flow**:
- Inputs `<o1>` and `<o2>` are processed independently by COMeT, then merged via green arrows.
- The merged output feeds into the Transformer, which refines embeddings through self-attention mechanisms.
---
### Key Observations
1. **Parameter Sharing**:
- Both `<o1>` and `<o2>` share identical parameter sets (`ω₁ ... ωₘ`), suggesting a unified processing mechanism for different inputs.
2. **Embedding Hierarchy**:
- COMeT embeddings (`c₁, c₉`) are distinct from word embeddings (`e₀ ... eₘ₊₁`), indicating a two-stage representation learning process.
3. **Contextualization**:
- The final `e₀ ... eₘ₊₁` embeddings are enriched by the Transformer, implying dynamic context integration.
---
### Interpretation
This architecture demonstrates a **multi-modal approach** to generating contextualized word representations:
- **COMeT Transformers** extract commonsense knowledge from structured inputs (`<o1>`, `<o2>`).
- The **central Transformer** combines these with lexical embeddings (`e₀ ... eₘ₊₁`) to produce context-aware representations.
- The use of shared parameters (`ω₁ ... ωₘ`) suggests efficiency, while the two-stage process (COMeT + Transformer) balances domain-specific knowledge with general language understanding.
**Notable Design Choices**:
- The `c₁, c₉` embeddings may represent specific commonsense concepts (e.g., causality, hierarchy).
- The `eₘ₊₁` output suggests the model handles variable-length sequences, common in transformer-based architectures.
This design aligns with modern NLP pipelines that integrate symbolic knowledge (COMeT) with neural contextualization (Transformer) for robust language understanding.