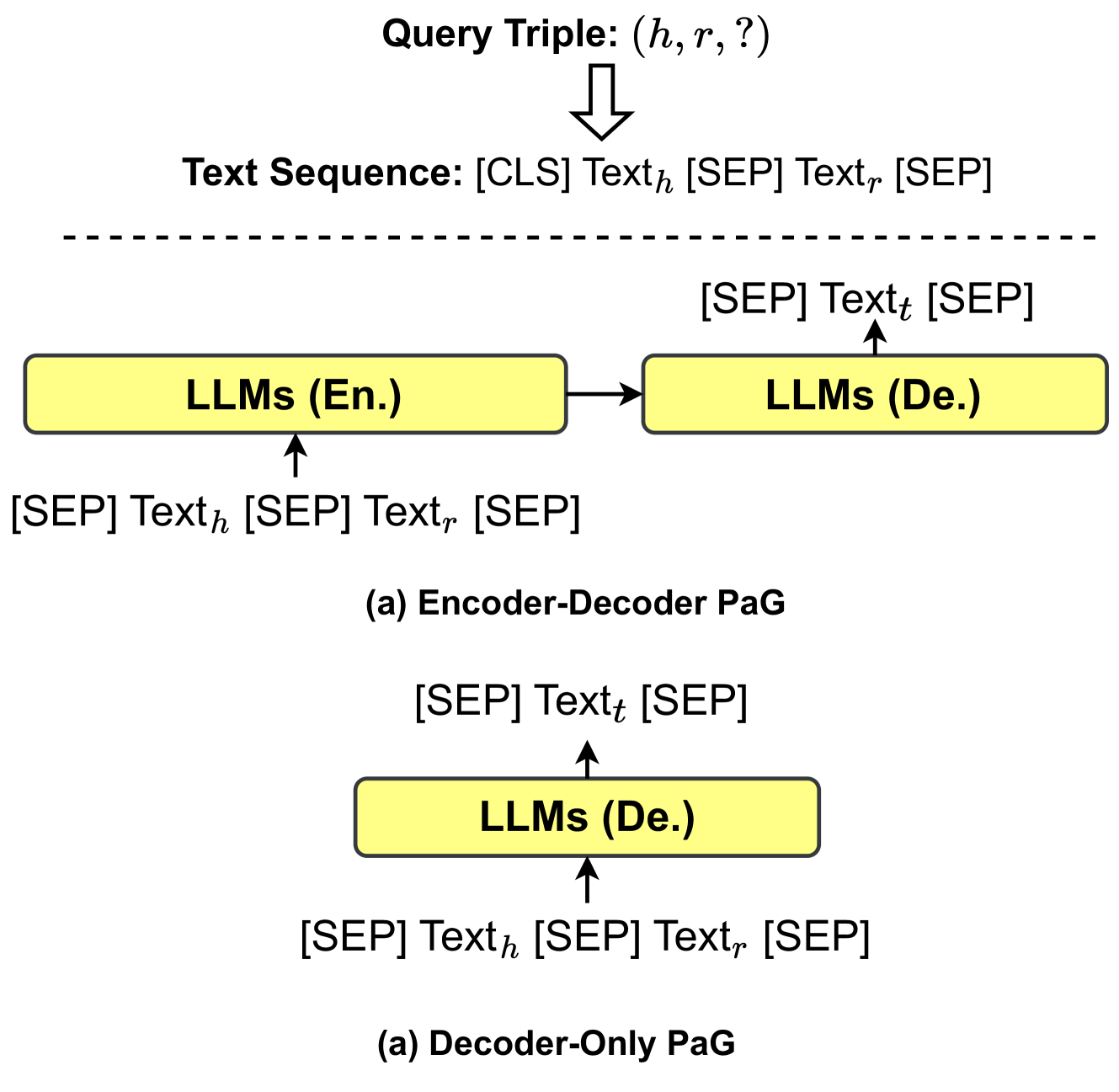
## Diagram: PaG Architectures - Encoder-Decoder vs. Decoder-Only
### Overview
The image presents a diagram illustrating two different architectures for Prompt-guided Generation (PaG) using Large Language Models (LLMs): an Encoder-Decoder model and a Decoder-Only model. The diagram visually represents the flow of information within each architecture, highlighting the roles of the LLMs and the input/output text sequences.
### Components/Axes
The diagram consists of two main sections, each representing a different PaG architecture. Each section includes:
* **Query Triple:** Represented as (h, r, ?).
* **Text Sequence:** Represented as [CLS] Text<sub>h</sub> [SEP] Text<sub>t</sub> [SEP].
* **LLMs (En.):** Large Language Models (English).
* **LLMs (De.):** Large Language Models (German).
* **Arrows:** Indicating the direction of information flow.
* **Labels:** "(a) Encoder-Decoder PaG" and "(b) Decoder-Only PaG" identifying each architecture.
* **Dashed Line:** Separating the Query Triple and Text Sequence from the LLM components in the Encoder-Decoder architecture.
### Detailed Analysis or Content Details
**Encoder-Decoder PaG (Top Section):**
1. **Input:** A "Query Triple" (h, r, ?) is shown at the top, with an arrow pointing downwards.
2. **Text Sequence:** Below the Query Triple, a "Text Sequence" is displayed: [CLS] Text<sub>h</sub> [SEP] Text<sub>t</sub> [SEP].
3. **LLMs (En.):** A yellow rectangle labeled "LLMs (En.)" is positioned on the left side. The text sequence [CLS] Text<sub>h</sub> [SEP] is shown below it, with an upward arrow indicating input.
4. **LLMs (De.):** A yellow rectangle labeled "LLMs (De.)" is positioned on the right side. An arrow points from "LLMs (En.)" to "LLMs (De.)", indicating information flow. The text sequence [SEP] Text<sub>t</sub> [SEP] is shown above it, with an upward arrow indicating input.
**Decoder-Only PaG (Bottom Section):**
1. **Input:** A "Query Triple" (h, r, ?) is implied, but not explicitly shown.
2. **Text Sequence:** A "Text Sequence" is displayed: [SEP] Text<sub>t</sub> [SEP].
3. **LLMs (De.):** A yellow rectangle labeled "LLMs (De.)" is positioned in the center. The text sequence [SEP] Text<sub>h</sub> [SEP] is shown below it, with an upward arrow indicating input.
**Language Notes:**
* "En." stands for English.
* "De." stands for German.
### Key Observations
* The Encoder-Decoder architecture utilizes two LLMs, one for encoding (En.) and one for decoding (De.).
* The Decoder-Only architecture utilizes only one LLM for decoding (De.).
* The text sequences differ slightly between the two architectures, reflecting the different roles of the LLMs.
* The dashed line in the Encoder-Decoder architecture visually separates the query and text input from the LLM processing.
### Interpretation
The diagram illustrates two distinct approaches to prompt-guided generation. The Encoder-Decoder model leverages the strengths of both encoding and decoding LLMs, potentially allowing for more complex transformations of the input text. The Encoder-Decoder architecture appears to be designed for translation or similar tasks where understanding the input (encoding) and generating a different output (decoding) are crucial. The Decoder-Only model simplifies the architecture by relying on a single LLM for both understanding and generation. This approach might be more efficient but could potentially sacrifice some of the nuanced understanding offered by the Encoder-Decoder model. The use of "[CLS]", "[SEP]", Text<sub>h</sub>, and Text<sub>t</sub> suggests a tokenization scheme commonly used in transformer-based LLMs, where Text<sub>h</sub> likely represents the head of the text and Text<sub>t</sub> represents the tail. The labels "En." and "De." indicate that the LLMs are trained on different languages, English and German respectively, suggesting a cross-lingual application of the PaG architectures. The diagram is a conceptual representation and does not provide specific data or numerical values. It focuses on the architectural differences and information flow.