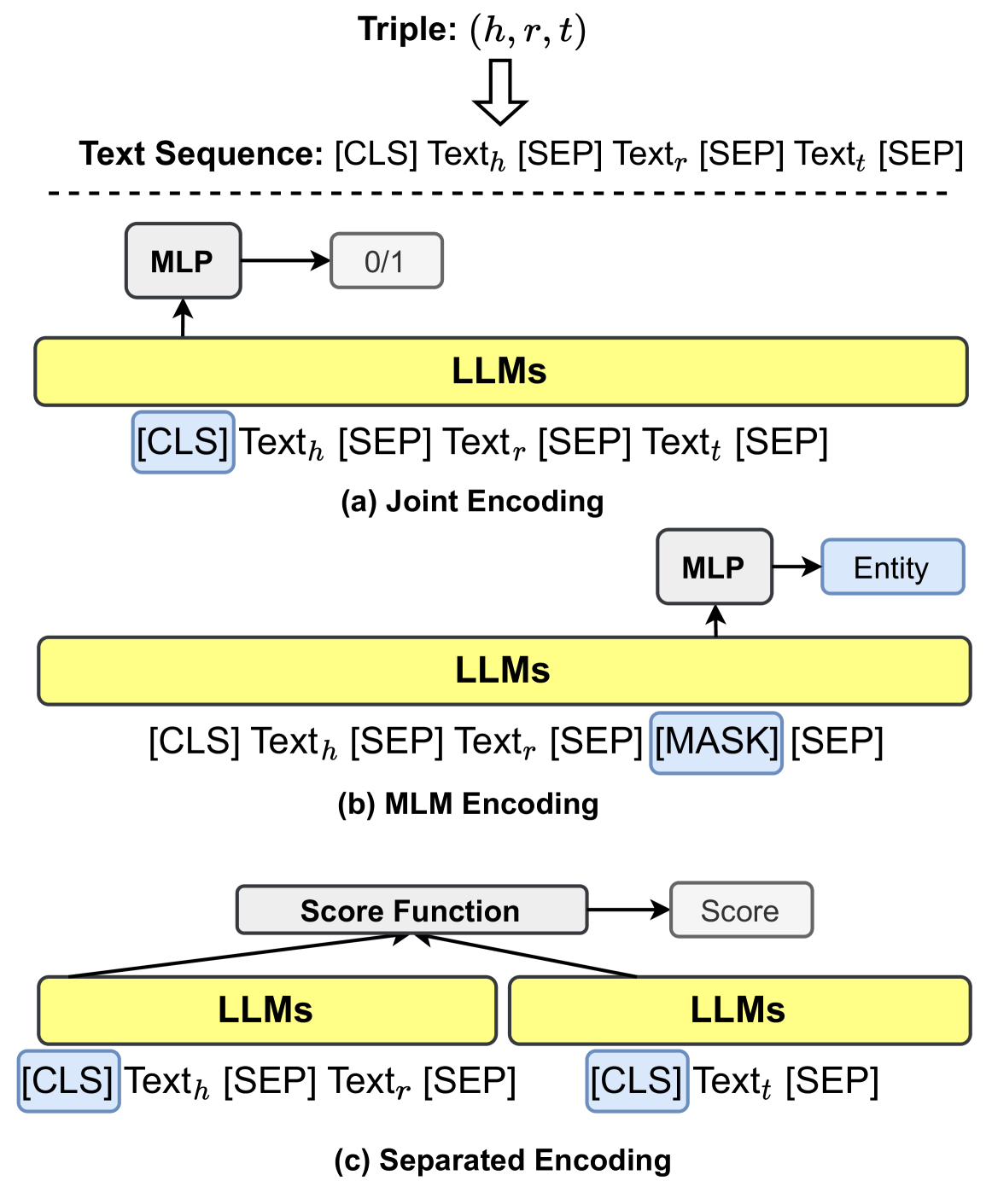
## Diagram: Triple Encoding Methods
### Overview
The image illustrates three different encoding methods for triples (h, r, t), likely representing head, relation, and tail entities in a knowledge graph. The methods are: Joint Encoding, MLM (Masked Language Model) Encoding, and Separated Encoding. Each method uses Large Language Models (LLMs) to process the input sequence and generate an output.
### Components/Axes
* **Triple:** (h, r, t) - Represents the head, relation, and tail entities.
* **Text Sequence:** [CLS] Texth [SEP] Textr [SEP] Textt [SEP] - The input sequence format for the LLMs.
* [CLS]: Classification token.
* Texth: Text representing the head entity.
* [SEP]: Separator token.
* Textr: Text representing the relation.
* Textt: Text representing the tail entity.
* [MASK]: Masked token.
* **LLMs:** Large Language Models - The core processing units. Represented as yellow rounded rectangles.
* **MLP:** Multi-Layer Perceptron - Used for further processing of the LLM output. Represented as gray rectangles.
* **0/1:** Output of the MLP in Joint Encoding, likely representing a binary classification score. Represented as a gray rounded rectangle.
* **Entity:** Output of the MLP in MLM Encoding, likely representing the predicted entity. Represented as a light blue rounded rectangle.
* **Score Function:** Used in Separated Encoding to combine the outputs of the two LLMs. Represented as a gray rectangle.
* **Score:** Output of the Score Function in Separated Encoding. Represented as a gray rounded rectangle.
### Detailed Analysis
**(a) Joint Encoding:**
* **Input Sequence:** `[CLS] Texth [SEP] Textr [SEP] Textt [SEP]`
* The entire sequence is fed into a single LLM.
* The output of the LLM is processed by an MLP.
* The MLP outputs a binary classification score (0/1).
**(b) MLM Encoding:**
* **Input Sequence:** `[CLS] Texth [SEP] Textr [SEP] [MASK] [SEP]`
* The tail entity (Textt) is replaced with a `[MASK]` token.
* The sequence is fed into a single LLM.
* The output of the LLM is processed by an MLP.
* The MLP outputs a predicted entity.
**(c) Separated Encoding:**
* The head and relation (`[CLS] Texth [SEP] Textr [SEP]`) and the tail (`[CLS] Textt [SEP]`) are fed into two separate LLMs.
* The outputs of the two LLMs are combined using a Score Function.
* The Score Function outputs a score.
### Key Observations
* The three encoding methods differ in how they process the triple information.
* Joint Encoding processes the entire triple at once.
* MLM Encoding uses a masked language model approach to predict the tail entity.
* Separated Encoding processes the head/relation and tail separately.
### Interpretation
The diagram illustrates three different approaches to encoding triples for knowledge graph tasks. The choice of encoding method can impact the performance of the model. Joint Encoding might be suitable for tasks that require reasoning over the entire triple. MLM Encoding might be suitable for tasks such as link prediction. Separated Encoding might be suitable for tasks where the head/relation and tail can be processed independently. The use of LLMs in all three methods highlights the importance of pre-trained language models in knowledge graph research.