\n
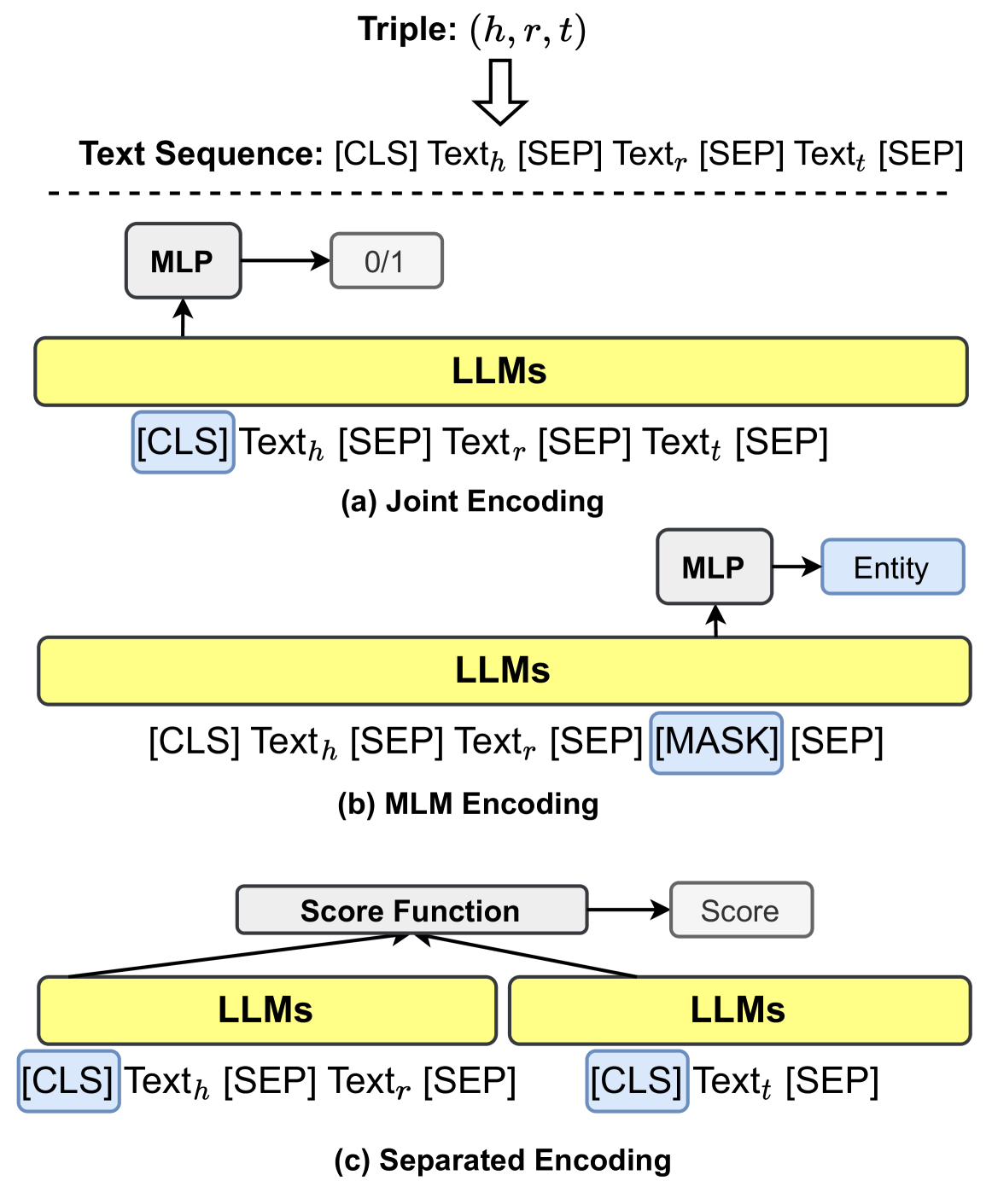
## Diagram: Relation Extraction Encoding Schemes
### Overview
This diagram illustrates three different encoding schemes for relation extraction using Large Language Models (LLMs). The schemes are labeled (a) Joint Encoding, (b) MLM Encoding, and (c) Separated Encoding. Each scheme takes a "Triple: (h, r, t)" as input and processes it through LLMs and other components to produce an output.
### Components/Axes
The diagram consists of three main sections, each representing a different encoding scheme. Each section includes:
* **LLMs:** Represented as yellow rectangles.
* **Text Sequence:** Shown above each LLM block, representing the input text.
* **MLP (Multi-Layer Perceptron):** Represented as grey rectangles.
* **Output:** Represented as rectangles with labels like "0/1", "Entity", and "Score".
* **Arrows:** Indicate the flow of information.
* **Triple:** (h, r, t) is shown at the top of the diagram.
### Detailed Analysis or Content Details
**Section (a): Joint Encoding**
* **Input:** Triple: (h, r, t) and Text Sequence: `[CLS] Text_h [SEP] Text_r [SEP] Text_t [SEP]`
* **LLM:** A single yellow rectangle labeled "LLMs".
* **MLP:** A grey rectangle connected to the LLM.
* **Output:** A rectangle labeled "0/1" connected to the MLP.
**Section (b): MLM Encoding**
* **Input:** Triple: (h, r, t) and Text Sequence: `[CLS] Text_h [SEP] Text_r [SEP] [MASK] [SEP]`
* **LLM:** A yellow rectangle labeled "LLMs".
* **MLP:** A grey rectangle connected to the LLM.
* **Output:** A rectangle labeled "Entity" connected to the MLP.
**Section (c): Separated Encoding**
* **Input:** Triple: (h, r, t)
* **LLMs:** Two yellow rectangles labeled "LLMs".
* **Text Sequence (LLM 1):** `[CLS] Text_h [SEP] Text_r [SEP]`
* **Text Sequence (LLM 2):** `[CLS] Text_t [SEP]`
* **Score Function:** A rectangle connecting the two LLMs.
* **Output:** A rectangle labeled "Score" connected to the Score Function.
### Key Observations
* The diagram highlights three distinct approaches to encoding relational information for LLMs.
* The Joint Encoding scheme combines the head, relation, and tail entities into a single text sequence.
* The MLM Encoding scheme uses a masked language modeling approach, replacing the tail entity with a `[MASK]` token.
* The Separated Encoding scheme processes the head/relation and tail entities separately.
* The use of special tokens like `[CLS]`, `[SEP]`, and `[MASK]` is consistent across all schemes.
### Interpretation
The diagram demonstrates different strategies for representing relational triples as input to LLMs. Each approach has potential trade-offs in terms of computational cost, expressiveness, and performance.
* **Joint Encoding** aims to capture the full context of the relation but might be limited by the LLM's ability to handle long sequences.
* **MLM Encoding** leverages the LLM's pre-training on masked language modeling tasks, potentially improving performance but requiring careful masking strategies.
* **Separated Encoding** allows for independent processing of the head and tail entities, potentially enabling more fine-grained analysis but losing some contextual information.
The diagram suggests a research direction focused on exploring the optimal encoding scheme for relation extraction tasks, considering the capabilities and limitations of LLMs. The choice of scheme likely depends on the specific dataset, LLM architecture, and desired performance characteristics. The diagram is a conceptual illustration and does not provide specific data or numerical results.