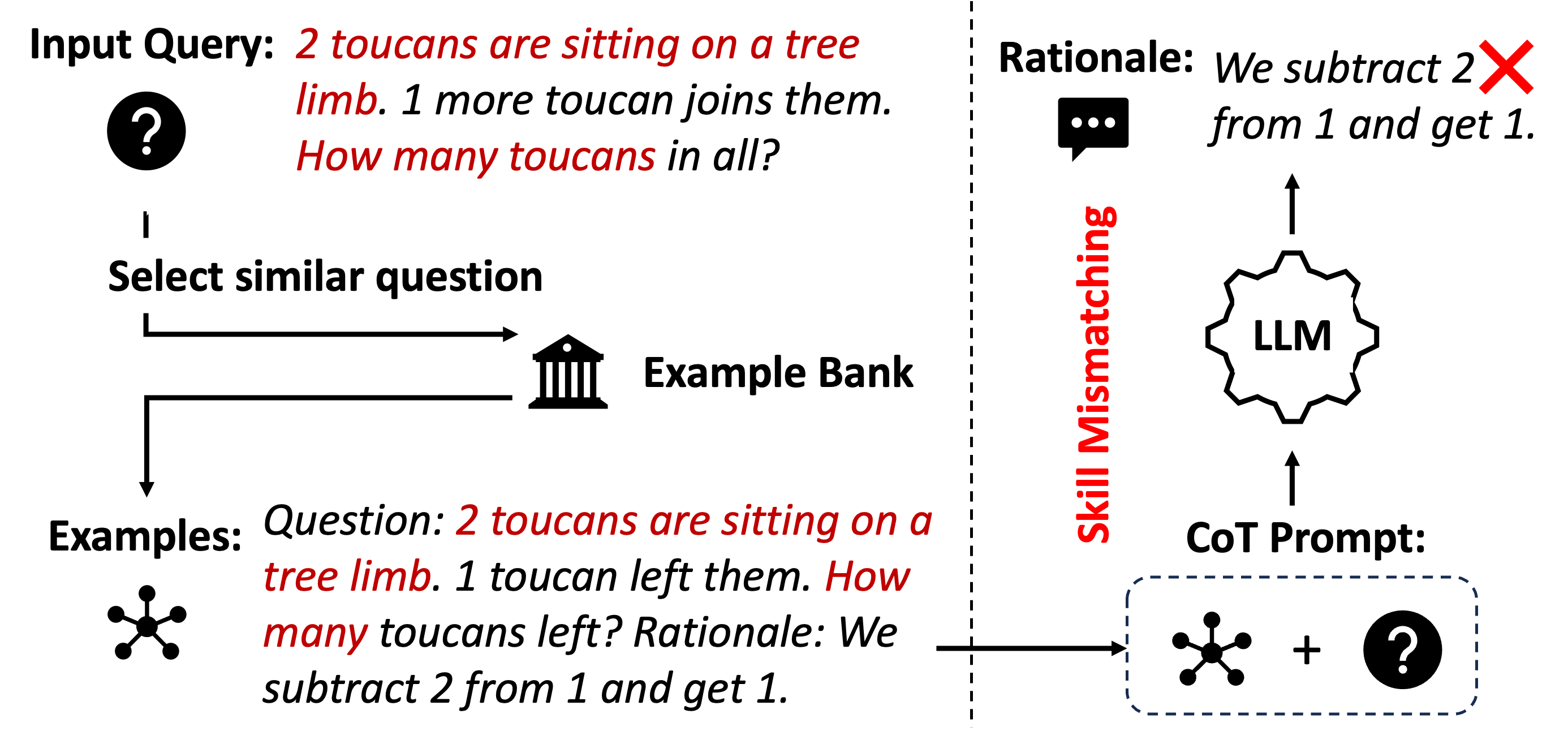
## Diagram: Skill Mismatching in Language Models
### Overview
The image illustrates a scenario where a language model (LLM) fails to correctly answer a question due to a skill mismatch. The diagram shows the flow of information from an input query to the LLM, highlighting how a similar question from an example bank can lead to an incorrect response.
### Components/Axes
* **Input Query:** "2 toucans are sitting on a tree limb. 1 more toucan joins them. How many toucans in all?" A question mark icon is placed to the left of the query.
* **Select similar question:** A process step where a similar question is selected.
* **Example Bank:** A repository of example questions and their rationales, represented by a building icon.
* **Examples:** "Question: 2 toucans are sitting on a tree limb. 1 toucan left them. How many toucans left? Rationale: We subtract 2 from 1 and get 1."
* **CoT Prompt:** Chain-of-Thought prompt, represented by a dashed rounded rectangle containing a star-like icon and a question mark icon connected by a plus sign.
* **LLM:** Language Model, represented by a gear-like icon.
* **Rationale:** "We subtract 2 from 1 and get 1." A speech bubble icon is placed to the left of the rationale. A red "X" is superimposed on the word "from".
* **Skill Mismatching:** A red label oriented vertically between the "Example Bank" and the "LLM".
### Detailed Analysis
1. **Input Query:** The initial question presented to the system. The question is about adding toucans.
2. **Select similar question:** The system attempts to find a similar question from the "Example Bank."
3. **Example Bank:** Contains an example question that involves subtraction ("1 toucan left them").
4. **Examples:** The example question and its rationale are shown. The rationale incorrectly states "We subtract 2 from 1 and get 1."
5. **CoT Prompt:** The example question and the input query are combined to form a Chain-of-Thought prompt.
6. **LLM:** The LLM processes the CoT prompt and generates a response based on the incorrect rationale from the example.
7. **Rationale:** The LLM produces an incorrect rationale, mirroring the error in the example ("We subtract 2 from 1 and get 1").
8. **Skill Mismatching:** The core issue is that the example question involves subtraction, while the input query requires addition. This mismatch leads the LLM to apply the wrong operation.
### Key Observations
* The diagram highlights how selecting a superficially similar question with a different underlying operation can lead to errors.
* The incorrect rationale in the example question is propagated to the LLM's response.
* The "Skill Mismatching" label emphasizes the fundamental problem.
### Interpretation
The diagram illustrates a common pitfall in using example-based learning for language models. If the examples are not carefully chosen to match the required skills for the input query, the LLM can learn and apply incorrect patterns. In this case, the LLM incorrectly applies subtraction because it was exposed to an example question that involved subtraction, even though the input query required addition. This demonstrates the importance of ensuring that the training data and examples used for prompting are aligned with the desired task and skills. The diagram suggests that a more robust system would need a better mechanism for selecting relevant examples or a way to prevent the LLM from being misled by irrelevant information.