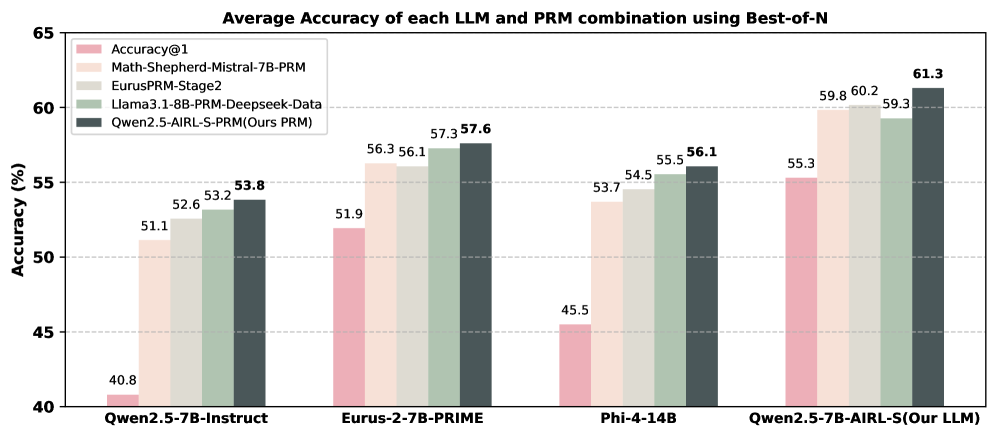
## Bar Chart: Average Accuracy of LLM and PRM Combinations
### Overview
The image is a bar chart comparing the average accuracy of different Large Language Model (LLM) and Prompt Relation Model (PRM) combinations using a "Best-of-N" approach. The chart displays accuracy percentages for four different LLM configurations, each tested with five different PRM setups.
### Components/Axes
* **Title:** Average Accuracy of each LLM and PRM combination using Best-of-N
* **Y-axis:** Accuracy (%), ranging from 40% to 65% with gridlines at 45%, 50%, 55%, and 60%.
* **X-axis:** Categorical axis representing different LLM configurations:
* Qwen2.5-7B-Instruct
* Eurus-2-7B-PRIME
* Phi-4-14B
* Qwen2.5-7B-AIRL-S(Our LLM)
* **Legend:** Located in the top-left corner, mapping PRM setups to bar colors:
* Accuracy@1 (light pink)
* Math-Shepherd-Mistral-7B-PRM (light beige)
* EurusPRM-Stage2 (light gray)
* Llama3.1-8B-PRM-Deepseek-Data (light green)
* Qwen2.5-AIRL-S-PRM(Ours PRM) (dark gray)
### Detailed Analysis
The chart presents accuracy values for each LLM configuration across the five PRM setups. Here's a breakdown:
* **Qwen2.5-7B-Instruct:**
* Accuracy@1: 40.8%
* Math-Shepherd-Mistral-7B-PRM: 51.1%
* EurusPRM-Stage2: 52.6%
* Llama3.1-8B-PRM-Deepseek-Data: 53.2%
* Qwen2.5-AIRL-S-PRM(Ours PRM): 53.8%
* **Eurus-2-7B-PRIME:**
* Accuracy@1: 51.9%
* Math-Shepherd-Mistral-7B-PRM: 56.3%
* EurusPRM-Stage2: 56.1%
* Llama3.1-8B-PRM-Deepseek-Data: 57.3%
* Qwen2.5-AIRL-S-PRM(Ours PRM): 57.6%
* **Phi-4-14B:**
* Accuracy@1: 45.5%
* Math-Shepherd-Mistral-7B-PRM: 53.7%
* EurusPRM-Stage2: 54.5%
* Llama3.1-8B-PRM-Deepseek-Data: 55.5%
* Qwen2.5-AIRL-S-PRM(Ours PRM): 56.1%
* **Qwen2.5-7B-AIRL-S(Our LLM):**
* Accuracy@1: 55.3%
* Math-Shepherd-Mistral-7B-PRM: 59.8%
* EurusPRM-Stage2: 60.2%
* Llama3.1-8B-PRM-Deepseek-Data: 59.3%
* Qwen2.5-AIRL-S-PRM(Ours PRM): 61.3%
### Key Observations
* The "Qwen2.5-7B-AIRL-S(Our LLM)" configuration generally achieves the highest accuracy across all PRM setups.
* The "Accuracy@1" PRM setup consistently yields the lowest accuracy compared to other PRM setups for each LLM configuration.
* The "Qwen2.5-7B-Instruct" configuration shows the lowest overall accuracy compared to the other LLM configurations.
* Using "Qwen2.5-AIRL-S-PRM(Ours PRM)" as the PRM setup generally results in the highest accuracy for each LLM configuration.
### Interpretation
The data suggests that the choice of both LLM and PRM significantly impacts the overall accuracy. The "Qwen2.5-7B-AIRL-S(Our LLM)" model, when combined with the "Qwen2.5-AIRL-S-PRM(Ours PRM)" prompt, appears to be the most effective combination, achieving the highest average accuracy. The "Accuracy@1" PRM setup seems to be the least effective across all LLMs tested. The results highlight the importance of optimizing both the language model and the prompting strategy to achieve optimal performance.