TECHNICAL ASSET FINGERPRINT
98fa335b1948b9b0eaf5fa9c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
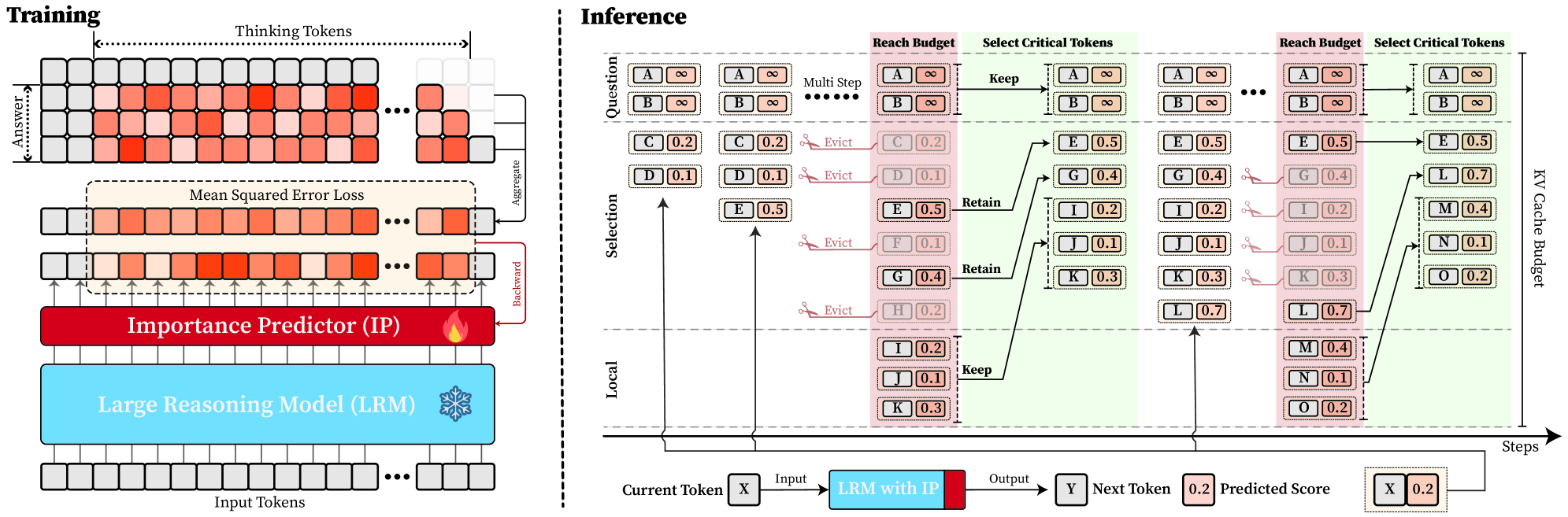
## Diagram: Training and Inference Process with Importance Predictor
### Overview
The image presents a diagram illustrating the training and inference processes of a Large Reasoning Model (LRM) enhanced with an Importance Predictor (IP). The diagram is split into two main sections: "Training" on the left and "Inference" on the right. The training section shows how the IP is trained using Mean Squared Error Loss, while the inference section demonstrates how the IP is used to manage a KV Cache Budget during multi-step reasoning.
### Components/Axes
**Training Section:**
* **Title:** Training
* **Elements:**
* Input Tokens: A series of gray boxes at the bottom, representing input tokens.
* Large Reasoning Model (LRM): A light blue box above the input tokens. A snowflake icon is present on the right side of the box.
* Importance Predictor (IP): A red box above the LRM. A flame icon is present on the right side of the box.
* Mean Squared Error Loss: A dashed box above the IP, containing a series of boxes with varying shades of red, representing the error loss.
* Thinking Tokens: A series of boxes with varying shades of red, representing the model's internal "thinking" process.
* Answer: A series of gray boxes, representing the correct answer.
* Arrows: Arrows indicate the flow of information:
* Upward arrows from the LRM to the IP and then to the Mean Squared Error Loss.
* "Aggregate" arrow pointing from the Thinking Tokens to the Mean Squared Error Loss.
* "Backward" arrow pointing from the Mean Squared Error Loss back to the IP.
**Inference Section:**
* **Title:** Inference
* **Axes:**
* Vertical Axis: Labeled "Selection" in the middle, and "Local" at the bottom.
* Horizontal Axis: Labeled "Steps" at the bottom-right, indicating the progression of the inference process.
* **Elements:**
* Question: Labeled at the top, containing token pairs A and B, each with a value of infinity.
* KV Cache Budget: Labeled on the right side, representing the memory allocated for key-value pairs.
* Reach Budget: A pink shaded region.
* Select Critical Tokens: A green shaded region.
* Tokens: Represented by boxes containing a letter and a numerical value. The color of the box indicates the token's importance or relevance.
* Arrows: Arrows indicate the flow of information and dependencies between tokens.
* Text Labels: "Evict," "Keep," and "Retain" indicate actions taken on tokens.
* Current Token: Labeled at the bottom-left, showing "Current Token X".
* LRM with IP: A light blue box with a red section on the right, representing the LRM enhanced with the IP.
* Next Token: Labeled at the bottom-right, showing "Next Token Y".
* Predicted Score: A box containing "0.2" with a red fill, representing the predicted score for the next token.
### Detailed Analysis
**Training Section:**
* The "Thinking Tokens" section shows a sequence of tokens, with the intensity of the red color indicating the level of "thinking" or processing associated with each token. The first 10 tokens are colored, with the 6th token being the most intense red. The last 3 tokens are gray.
* The "Mean Squared Error Loss" section shows a similar sequence of tokens, with the intensity of the red color indicating the magnitude of the error. The 6th token is the most intense red.
* The "Importance Predictor (IP)" receives input from the "Large Reasoning Model (LRM)" and is trained using the "Mean Squared Error Loss."
**Inference Section:**
* The "Question" tokens A and B have infinite values and are kept throughout the process.
* The "Selection" section shows a series of tokens (C, D, E, F, G, H) with associated values (0.2, 0.1, 0.5, 0.1, 0.4, 0.2). Some tokens are evicted based on their values.
* The "Local" section shows tokens (I, J, K) with associated values (0.2, 0.1, 0.3). These tokens are kept.
* The "Reach Budget" region highlights tokens that are considered for retention in the KV Cache.
* The "Select Critical Tokens" region shows the tokens that are ultimately retained in the KV Cache.
* The KV Cache Budget section shows the final set of tokens (L, M, N, O) with associated values (0.7, 0.4, 0.1, 0.2).
* The process starts with a "Current Token X," which is fed into the "LRM with IP" to predict the "Next Token Y" and its associated score.
**Token Values and Actions:**
| Token | Value | Action (Inference) |
|-------|-------|--------------------|
| A | ∞ | Keep |
| B | ∞ | Keep |
| C | 0.2 | Evict |
| D | 0.1 | Evict |
| E | 0.5 | Retain |
| F | 0.1 | Evict |
| G | 0.4 | Retain |
| H | 0.2 | Evict |
| I | 0.2 | Keep |
| J | 0.1 | Keep |
| K | 0.3 | Keep |
| L | 0.7 | - |
| M | 0.4 | - |
| N | 0.1 | - |
| O | 0.2 | - |
### Key Observations
* The "Training" section focuses on minimizing the error between the model's "thinking" process and the correct answer.
* The "Inference" section demonstrates how the IP is used to selectively retain important tokens in the KV Cache, optimizing memory usage and potentially improving performance.
* Tokens with higher values are more likely to be retained in the KV Cache.
* The "Reach Budget" and "Select Critical Tokens" regions visually represent the token selection process.
### Interpretation
The diagram illustrates a system where an Importance Predictor (IP) is trained to identify and retain critical tokens during the inference process of a Large Reasoning Model (LRM). The training process uses Mean Squared Error Loss to refine the IP's ability to predict the importance of tokens. During inference, the IP helps manage the KV Cache Budget by selectively retaining tokens based on their predicted importance, as indicated by their numerical values. This approach aims to optimize memory usage and potentially improve the efficiency and performance of the LRM by focusing on the most relevant information. The "Evict," "Keep," and "Retain" actions demonstrate the dynamic management of the KV Cache, highlighting the IP's role in prioritizing and preserving important tokens while discarding less relevant ones.
DECODING INTELLIGENCE...