TECHNICAL ASSET FINGERPRINT
98fa335b1948b9b0eaf5fa9c
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
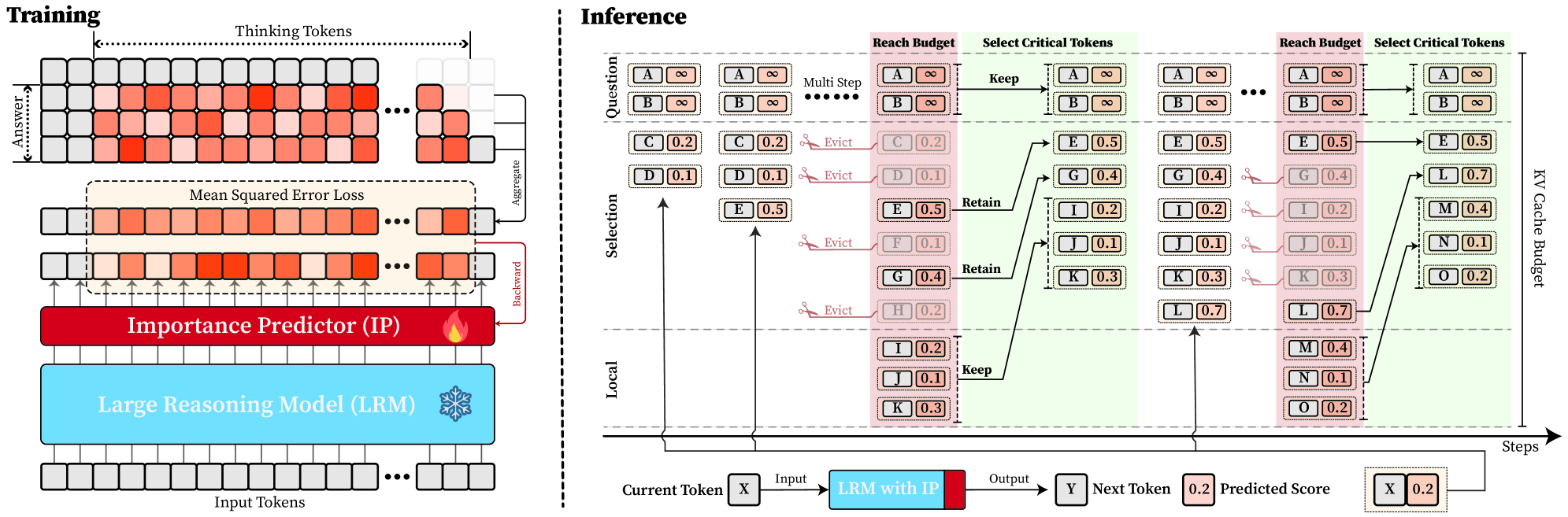
## Diagram: Large Reasoning Model (LRM) with Importance Predictor (IP) - Training and Inference Architecture
### Overview
This technical diagram illustrates the architecture and workflow of a system that augments a Large Reasoning Model (LRM) with a trainable Importance Predictor (IP). The system is designed to optimize the Key-Value (KV) cache during inference by predicting the importance of tokens and selectively retaining or evicting them to meet a computational budget. The diagram is split into two primary sections: **Training** (left) and **Inference** (right).
### Components/Axes
The diagram is a flowchart/block diagram with the following major components and labels:
**Training Section (Left Panel):**
* **Input Tokens:** A sequence of grey squares at the bottom, representing the initial input.
* **Large Reasoning Model (LRM):** A large blue block labeled "Large Reasoning Model (LRM)" with a snowflake icon (❄️), indicating it is a frozen (non-trainable) component.
* **Importance Predictor (IP):** A red block labeled "Importance Predictor (IP)" with a fire icon (🔥), indicating it is a trainable component. It sits above the LRM.
* **Thinking Tokens:** A grid of squares above the IP, color-coded in shades of orange/red. A label "Thinking Tokens" with a double-headed arrow spans the top of this grid.
* **Answer:** A vertical label on the left side of the Thinking Tokens grid.
* **Mean Squared Error Loss:** A dashed box encompassing a row of orange/red squares, labeled "Mean Squared Error Loss".
* **Aggregate:** An arrow pointing from the right end of the Thinking Tokens grid to the loss calculation.
* **Backward:** An arrow pointing from the loss calculation back to the Importance Predictor (IP), indicating the backpropagation path for training.
**Inference Section (Right Panel):**
* **Steps:** A horizontal axis at the bottom labeled "Steps", indicating the progression of the inference process.
* **KV Cache Budget:** A vertical label on the far right, indicating the constraint on the cache size.
* **Multi Step:** A label at the top left of the inference flow.
* **Token Blocks:** Tokens are represented as pairs of boxes (e.g., `[A][∞]`, `[C][0.2]`). The first box contains a letter (token identifier), and the second contains a numerical score (predicted importance) or the infinity symbol (∞).
* **Process Labels:** The flow is annotated with labels: "Question", "Selection", "Local", "Reach Budget", "Select Critical Tokens", "Keep", "Evict", and "Retain".
* **LRM with IP:** A combined blue and red block at the bottom, labeled "LRM with IP".
* **Current Token / Next Token:** Boxes labeled "X" (Current Token) and "Y" (Next Token).
* **Predicted Score:** A box showing a numerical value (e.g., `0.2`).
**Color Coding & Legend:**
* **Grey Squares:** Input tokens, non-critical tokens, or evicted tokens.
* **Orange/Red Squares:** "Thinking Tokens" or tokens with high predicted importance scores.
* **Blue Block:** Frozen LRM component.
* **Red Block:** Trainable Importance Predictor (IP) component.
* **Pink/Red Background Shading:** Highlights tokens involved in the "Evict" action.
* **Green Background Shading:** Highlights the final set of retained tokens within the "KV Cache Budget".
### Detailed Analysis
The diagram details a two-phase process:
**1. Training Phase:**
* Input tokens are fed into the frozen **Large Reasoning Model (LRM)**.
* The LRM produces "Thinking Tokens" (a sequence of hidden states or activations).
* The trainable **Importance Predictor (IP)** processes these tokens.
* The system calculates a **Mean Squared Error Loss** by comparing the IP's predictions against an aggregated target derived from the thinking tokens.
* The loss is backpropagated (**Backward** arrow) to update only the Importance Predictor (IP), leaving the LRM frozen.
**2. Inference Phase (Multi-Step Process):**
The process flows from left to right across multiple steps, governed by a **KV Cache Budget**.
* **Initial State:** A set of tokens (A, B, C, D, E...) with their predicted importance scores (e.g., A: ∞, B: ∞, C: 0.2, D: 0.1, E: 0.5).
* **Selection & Eviction:** Based on the scores and the budget, tokens are processed:
* Tokens with infinite score (∞) or high score (e.g., E: 0.5) are **Kept** or **Retained**.
* Tokens with low scores (e.g., C: 0.2, D: 0.1, F: 0.1, H: 0.2) are marked for **Evict**ion (shown with scissors icons and pink background).
* **Local Context:** A separate set of recent tokens (I, J, K) is always **Kept** in a local cache.
* **Budget Enforcement:** The system selects the critical tokens (those not evicted and the local context) to fit within the **KV Cache Budget** (green shaded area). For example, after eviction, the retained set might be A, B, E, G, I, J, K.
* **Next Step Generation:** The current token (X) and the retained KV cache are input to the **LRM with IP**. The model outputs the next token (Y) and a new predicted importance score (e.g., 0.2) for the current token (X), which is then added to the cache for the next step. This cycle repeats.
### Key Observations
* **Selective Retention:** The core mechanism is the dynamic selection of tokens based on a learned importance score, not just recency.
* **Budget-Conscious:** The entire inference process is constrained by a predefined **KV Cache Budget**, forcing a trade-off between context length and computational efficiency.
* **Hybrid Cache:** The cache appears to consist of two parts: a **budget-constrained set** of historically important tokens and a **fixed local context** of recent tokens.
* **Training Focus:** Only the Importance Predictor is trained, using a self-supervised signal (MSE loss on thinking tokens), making the approach potentially efficient.
* **Symbolism:** The snowflake (❄️) on the LRM and fire (🔥) on the IP clearly distinguish between frozen and trainable components.
### Interpretation
This diagram presents a method for making large reasoning models more efficient during inference. The key innovation is decoupling the "reasoning" capability (frozen in the massive LRM) from the "memory management" capability (trainable in the lightweight IP).
The system learns *what to remember*. Instead of naively keeping all previous tokens in the KV cache (which grows linearly and becomes prohibitively expensive), it trains a predictor to assign importance scores. During inference, it actively curates the cache, evicting low-importance tokens to stay within a fixed budget. This allows the model to maintain a long effective context (by keeping critical past information) while controlling computational cost and memory usage.
The "Thinking Tokens" and the use of MSE loss suggest the IP is trained to predict which intermediate states of the LRM's reasoning process are most valuable for future generation. The multi-step inference flow demonstrates a practical, closed-loop system where the model's own predictions (both for the next token and for token importance) continuously update its working memory. This represents a shift from static context windows to dynamic, learned memory management for large language models.
DECODING INTELLIGENCE...