## Diagram: Reinforcement Learning Process & Question Rephrasing
### Overview
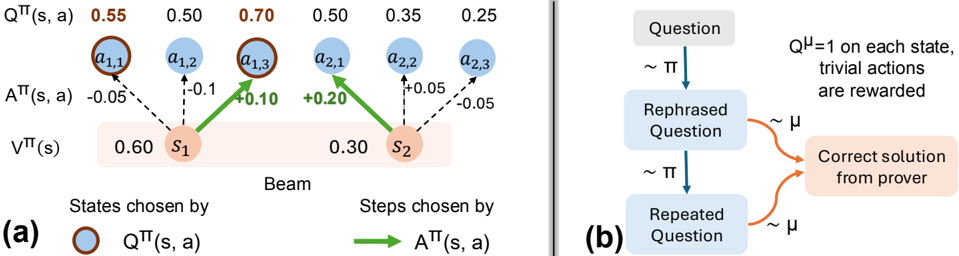
The image presents two diagrams, labeled (a) and (b), illustrating components of a reinforcement learning process and a question rephrasing mechanism. Diagram (a) depicts a state transition diagram with Q-values and policy values, while diagram (b) shows a flow chart for rephrasing questions and obtaining solutions.
### Components/Axes
**Diagram (a):**
* **States:** s1, s2
* **Actions:** a1,1, a1,2, a1,3, a2,1, a2,2, a2,3
* **Q-values:** Q<sup>π</sup>(s, a) – values ranging from 0.25 to 0.70.
* **Policy Values:** V<sup>π</sup>(s) – 0.60 for s1 and 0.30 for s2.
* **Policy Transition Weights:** A<sup>π</sup>(s, a) – values ranging from -0.10 to +0.20.
* **Legend:**
* Blue circles: Q<sup>π</sup>(s, a)
* Green arrows: A<sup>π</sup>(s, a)
* **Label:** "Beam" – positioned below states s1 and s2.
**Diagram (b):**
* **Input:** "Question"
* **Process:** "Rephrased Question", "Repeated Question"
* **Output:** "Correct solution from prover"
* **Distribution:** ~π (sampling from a policy) and ~μ (sampling from a distribution)
* **Reward:** Q<sup>μ</sup> = 1 on each state, trivial actions are rewarded.
* **Arrows:** Indicate flow of information.
### Detailed Analysis or Content Details
**Diagram (a):**
* **State s1:**
* Q<sup>π</sup>(s1, a1,1) = 0.55
* Q<sup>π</sup>(s1, a1,2) = 0.50
* Q<sup>π</sup>(s1, a1,3) = 0.70
* V<sup>π</sup>(s1) = 0.60
* A<sup>π</sup>(s1, a1,1) = -0.05
* A<sup>π</sup>(s1, a1,2) = -0.10
* A<sup>π</sup>(s1, a1,3) = +0.20
* **State s2:**
* Q<sup>π</sup>(s2, a2,1) = 0.50
* Q<sup>π</sup>(s2, a2,2) = 0.35
* Q<sup>π</sup>(s2, a2,3) = 0.25
* V<sup>π</sup>(s2) = 0.30
* A<sup>π</sup>(s2, a2,1) = +0.05
* A<sup>π</sup>(s2, a2,2) = -0.05
**Diagram (b):**
* A "Question" is fed into a process that generates a "Rephrased Question" sampled from a policy π.
* The "Rephrased Question" leads to a "Correct solution from prover".
* The process is repeated with a "Repeated Question" also sampled from policy π.
* The "Repeated Question" is sampled from a distribution μ.
* The reward function Q<sup>μ</sup> assigns a value of 1 to each state, rewarding trivial actions.
### Key Observations
* In diagram (a), the Q-values for state s1 are generally higher than those for state s2, suggesting s1 is a more desirable state.
* The policy transition weights (A<sup>π</sup>(s, a)) indicate the probability of taking specific actions from each state. Positive values suggest a higher probability, while negative values suggest a lower probability.
* Diagram (b) illustrates an iterative process of question rephrasing and solution seeking, potentially aiming to improve the quality or accuracy of the solutions obtained.
### Interpretation
Diagram (a) represents a simplified reinforcement learning environment. The Q-values represent the expected cumulative reward for taking a specific action in a given state, following a particular policy (π). The policy values (V<sup>π</sup>(s)) represent the expected cumulative reward for being in a given state, following the same policy. The policy transition weights (A<sup>π</sup>(s, a)) show the probability of taking each action from each state. The "Beam" label suggests a beam search algorithm might be used to explore the state space.
Diagram (b) depicts a mechanism for refining questions to obtain better solutions. The rephrasing process, guided by a policy π, aims to generate questions that are more likely to elicit correct answers. The iterative nature of the process, with repeated questioning and sampling from distribution μ, suggests a search for optimal question formulations. The reward function Q<sup>μ</sup> incentivizes trivial actions, potentially indicating a need to balance exploration and exploitation in the question-answering process.
The two diagrams together suggest a system where reinforcement learning is used to guide the rephrasing of questions, ultimately leading to improved solution quality. The system appears to be designed to explore different question formulations and learn which ones are most effective in eliciting correct answers.