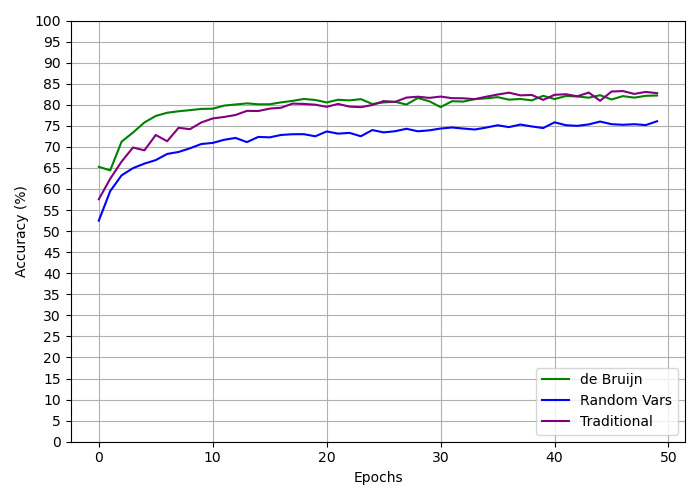
## Line Chart: Accuracy Comparison of Three Methods Over Training Epochs
### Overview
The image is a line chart comparing the training accuracy (in percentage) of three different methods or models over 50 training epochs. The chart demonstrates the learning curves, showing how accuracy improves with training time for each approach.
### Components/Axes
* **Chart Type:** Line chart with grid lines.
* **X-Axis:** Labeled "Epochs". Scale ranges from 0 to 50, with major tick marks and grid lines at intervals of 10 (0, 10, 20, 30, 40, 50).
* **Y-Axis:** Labeled "Accuracy (%)". Scale ranges from 0 to 100, with major tick marks and grid lines at intervals of 5 (0, 5, 10, ..., 95, 100).
* **Legend:** Located in the bottom-right corner of the chart area. It contains three entries:
* A green line labeled "de Bruijn"
* A blue line labeled "Random Vars"
* A purple line labeled "Traditional"
### Detailed Analysis
**Trend Verification & Data Points (Approximate):**
1. **de Bruijn (Green Line):**
* **Trend:** Starts highest, shows a very steep initial increase, then plateaus at a high level with minor fluctuations.
* **Key Points:**
* Epoch 0: ~65%
* Epoch 5: ~78%
* Epoch 10: ~80%
* Epoch 20: ~81%
* Epoch 30: ~82%
* Epoch 40: ~82%
* Epoch 50: ~83%
2. **Traditional (Purple Line):**
* **Trend:** Starts in the middle, increases rapidly, converges with and occasionally surpasses the "de Bruijn" line after epoch 20, ending at a similar high accuracy.
* **Key Points:**
* Epoch 0: ~57%
* Epoch 5: ~70%
* Epoch 10: ~78%
* Epoch 20: ~80% (intersects with green line)
* Epoch 30: ~82%
* Epoch 40: ~83% (appears slightly above green line)
* Epoch 50: ~83%
3. **Random Vars (Blue Line):**
* **Trend:** Starts the lowest, shows a steady but less steep increase compared to the others, and plateaus at a significantly lower accuracy level.
* **Key Points:**
* Epoch 0: ~53%
* Epoch 5: ~65%
* Epoch 10: ~72%
* Epoch 20: ~74%
* Epoch 30: ~75%
* Epoch 40: ~76%
* Epoch 50: ~76%
### Key Observations
* **Performance Hierarchy:** The "de Bruijn" and "Traditional" methods achieve final accuracies within 1-2 percentage points of each other (~82-83%), while "Random Vars" consistently underperforms, plateauing around 76%.
* **Learning Speed:** "de Bruijn" has the fastest initial learning, reaching ~78% by epoch 5. "Traditional" starts slower but catches up by epoch 20. "Random Vars" has the slowest learning rate throughout.
* **Convergence:** The "Traditional" and "de Bruijn" lines converge and become intertwined after approximately epoch 20, suggesting similar final model performance despite different starting points and initial learning dynamics.
* **Stability:** All three lines show minor epoch-to-epoch fluctuations after their initial rise, but no dramatic drops or spikes, indicating stable training.
### Interpretation
This chart likely compares different weight initialization strategies or architectural approaches for a machine learning model. The data suggests that structured initialization or methods ("de Bruijn" sequences and "Traditional" approaches) lead to significantly better final model accuracy and faster initial learning compared to a random initialization ("Random Vars").
The near-identical final performance of "de Bruijn" and "Traditional" methods implies that for this specific task, both are equally effective at reaching an optimal solution, though "de Bruijn" may offer a slight advantage in the very early stages of training. The persistent gap between these two and the "Random Vars" line highlights the importance of informed initialization or methodological structure in achieving higher model performance. The plateauing of all curves indicates that the models have likely reached their capacity or the limit of learnable information from the dataset by around 30-40 epochs.