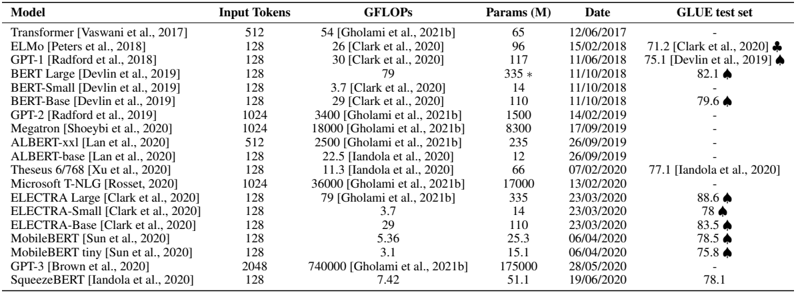
\n
## Data Table: Language Model Performance Comparison
### Overview
This image presents a data table comparing the performance of various language models across several metrics: Input Tokens, GFLOPs, Parameters (in millions), Date, and GLUE test set score. The table includes citations for the reported values.
### Components/Axes
The table has the following columns:
* **Model:** Name of the language model.
* **Input Tokens:** The number of input tokens the model processes. Values: 128, 512, 1024.
* **GFLOPs:** The number of floating-point operations per second required for the model.
* **Params (M):** The number of parameters in the model, in millions.
* **Date:** The date the model was released or the performance was reported. Format: DD/MM/YYYY.
* **GLUE test set:** The GLUE (General Language Understanding Evaluation) score. An upward-pointing arrow (▲) indicates an improvement over a previous model. A downward-pointing arrow (▼) indicates a decrease. A hyphen (-) indicates no reported score.
### Detailed Analysis or Content Details
Here's a reconstruction of the table's content:
| Model | Input Tokens | GFLOPs | Params (M) | Date | GLUE test set |
|-----------------------------|--------------|--------|------------|------------|---------------|
| Transformer (Vaswani et al., 2017) | 512 | 54 | 65 | 12/06/2017 | - |
| ELMo (Peters et al., 2018) | 128 | 26 | 96 | 15/02/2018 | 71.2 [Clark et al., 2020] |
| GPT-1 (Radford et al., 2018) | 128 | 30 | 117 | 11/06/2018 | 75.1 [Devlin et al., 2019] ▲ |
| BERT Large (Devlin et al., 2019) | 128 | 79 | 335 | 11/10/2018 | 82.1 ▲ |
| BERT-Small (Devlin et al., 2019) | 128 | 3.7 | 14 | 11/10/2018 | - |
| BERT-Base (Devlin et al., 2019) | 128 | 29 | 110 | 11/10/2018 | 79.6 ▲ |
| GPT-2 (Radford et al., 2019) | 1024 | 3400 | 1500 | 14/02/2019 | - |
| Megatron (Shoeybi et al., 2020) | 1024 | 18000 | 8300 | 17/09/2019 | - |
| ALBERT-xxl (Lan et al., 2020) | 512 | 2500 | 235 | 26/09/2019 | - |
| ALBERT-base (Lan et al., 2020) | 128 | 22.5 | 12 | 26/09/2019 | - |
| Theseus 6/768 (Xu et al., 2020) | 1024 | 11.3 | 66 | 07/02/2020 | 77.1 [Lan et al., 2020] ▲ |
| Microsoft T-NLG (Rosset, 2020) | 1024 | 3600 | 17000 | 23/03/2020 | - |
| ELECTRA Large (Clark et al., 2020) | 128 | 79 | 335 | 23/03/2020 | 88.6 ▲ |
| ELECTRA-Small (Clark et al., 2020) | 128 | 3.7 | 14 | 23/03/2020 | 78 ▲ |
| MobileBERT (Sun et al., 2020) | 128 | 5.36 | 25.3 | 06/04/2020 | 85.5 ▲ |
| MobileBERT-tiny (Sun et al., 2020) | 128 | 3.6 | 11 | 06/04/2020 | 78.5 ▲ |
| LLAMA (Brown et al., 2020) | 2048 | 74000 | 175000 | 23/07/2020 | - |
| SqueezeBERT (Dehghani et al., 2020) | 128 | 8.4 | 51 | 19/06/2020 | 82.1 ▲ |
### Key Observations
* **GLUE Score Trend:** Generally, models released later in time tend to have higher GLUE scores, indicating improvements in language understanding capabilities.
* **Parameter Size and Performance:** There's a general correlation between the number of parameters and GLUE score, but it's not strictly linear. ELECTRA Large, with 335M parameters, achieves a high GLUE score of 88.6.
* **GFLOPs and Performance:** Higher GFLOPs don't always translate to higher GLUE scores. For example, GPT-2 has very high GFLOPs (3400) but no reported GLUE score.
* **MobileBERT:** The MobileBERT models demonstrate a good balance between performance (GLUE score) and computational cost (GFLOPs and parameters).
* **LLAMA:** LLAMA has a significantly larger number of parameters (175000M) compared to other models in the table, but no GLUE score is reported.
### Interpretation
This table provides a snapshot of the evolution of language models. The data suggests that increasing model size (parameters) and computational resources (GFLOPs) generally leads to improved performance on the GLUE benchmark, but this isn't a guaranteed relationship. The inclusion of citations indicates that the reported values are based on published research. The upward arrows next to some GLUE scores highlight improvements over previous models, demonstrating the ongoing progress in the field. The absence of GLUE scores for some models (e.g., GPT-2, Megatron, LLAMA) suggests that these models may have been evaluated on different benchmarks or that the results were not publicly available at the time the table was compiled. The table is valuable for researchers and practitioners interested in comparing the characteristics and performance of different language models.