# Technical Document Extraction: Transformer Block Architecture
## 1. Overview
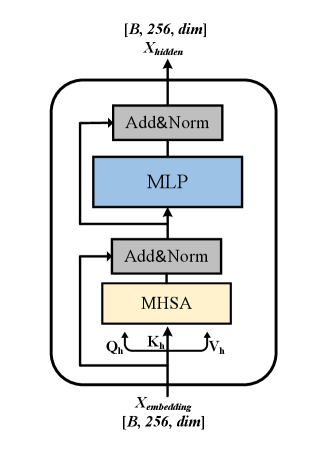
The image illustrates a technical diagram of a single Transformer encoder block, commonly used in deep learning architectures for natural language processing and computer vision. It details the flow of data through multi-head self-attention and feed-forward layers, including residual connections and normalization steps.
## 2. Component Isolation
### Header (Output Section)
* **Label:** $X_{hidden}$
* **Tensor Shape:** $[B, 256, dim]$
* *B*: Batch size.
* *256*: Sequence length or number of tokens.
* *dim*: Embedding dimensionality.
### Main Chart (Internal Architecture)
The architecture is contained within a rounded rectangular boundary, representing a single repeatable layer. It consists of two primary sub-blocks, each utilizing a residual (skip) connection.
#### Sub-block 1: Attention Mechanism
* **MHSA (Multi-Head Self-Attention):** Represented by a light yellow rectangle.
* **Inputs to MHSA:** The input stream splits into three components:
* $Q_h$ (Queries)
* $K_h$ (Keys)
* $V_h$ (Values)
* **Add&Norm:** Represented by a grey rectangle. This layer performs an element-wise addition of the original input (via a skip connection) and the MHSA output, followed by Layer Normalization.
#### Sub-block 2: Feed-Forward Network
* **MLP (Multi-Layer Perceptron):** Represented by a light blue rectangle. This is the position-wise feed-forward network.
* **Add&Norm:** Represented by a grey rectangle. This layer performs an element-wise addition of the input to the MLP (via a skip connection) and the MLP output, followed by Layer Normalization.
### Footer (Input Section)
* **Label:** $X_{embedding}$
* **Tensor Shape:** $[B, 256, dim]$
* Matches the output shape, indicating a transformation that preserves dimensionality.
---
## 3. Data Flow and Logic Verification
### Flow Description
1. **Input:** The process begins at the bottom with $X_{embedding}$.
2. **Branching:** The input path splits. One path goes directly into the first **Add&Norm** (the residual connection). The other path splits into $Q_h, K_h, V_h$ and enters the **MHSA** block.
3. **First Integration:** The output of MHSA and the residual connection are combined in the first **Add&Norm** block.
4. **Second Branching:** The output of the first Add&Norm splits. One path goes directly to the second **Add&Norm** (the second residual connection). The other path enters the **MLP** block.
5. **Second Integration:** The output of the MLP and the second residual connection are combined in the final **Add&Norm** block.
6. **Output:** The final result is $X_{hidden}$ at the top of the diagram.
### Trend/Logic Check
* **Dimensionality Consistency:** The input and output shapes are identical ($[B, 256, dim]$), which is consistent with standard Transformer block designs that allow for stacking multiple layers.
* **Residual Pathing:** The arrows clearly indicate that the "Add" part of "Add&Norm" receives the unprocessed input from the start of that specific sub-section, bypassing the heavy computation (MHSA or MLP) to mitigate vanishing gradient issues.
## 4. Textual Transcriptions
| Element Type | Text / Symbol | Description |
| :--- | :--- | :--- |
| **Input Variable** | $X_{embedding}$ | The input tensor to the block. |
| **Output Variable** | $X_{hidden}$ | The processed output tensor. |
| **Dimensions** | $[B, 256, dim]$ | Batch size, sequence length, and feature dimension. |
| **Component 1** | MHSA | Multi-Head Self-Attention. |
| **Component 2** | MLP | Multi-Layer Perceptron (Feed-forward). |
| **Component 3** | Add&Norm | Addition (Residual) and Layer Normalization. |
| **Attention Vectors** | $Q_h, K_h, V_h$ | Query, Key, and Value vectors for the attention mechanism. |