\n
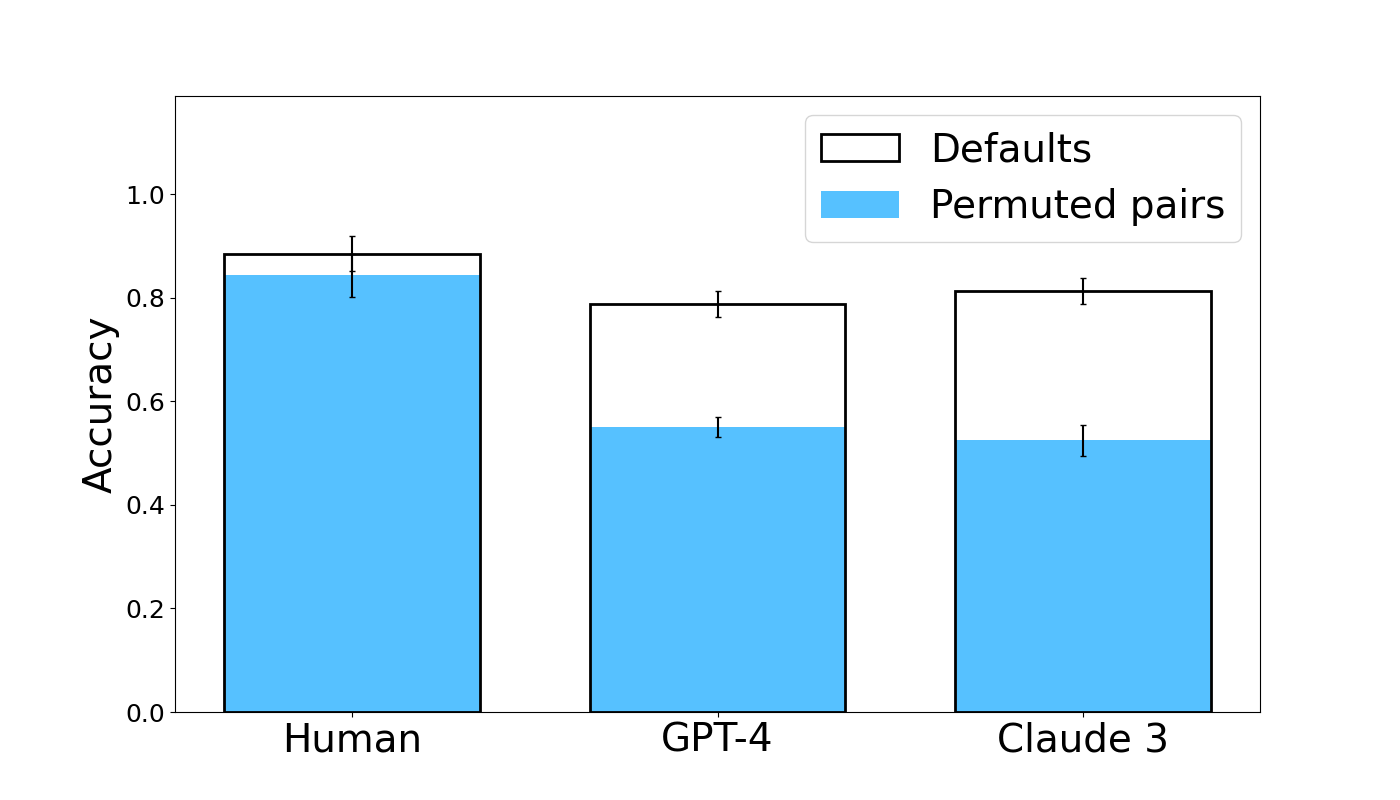
## Bar Chart: Accuracy Comparison - Human, GPT-4, and Claude 3
### Overview
This bar chart compares the accuracy of three entities – Human, GPT-4, and Claude 3 – under two conditions: "Defaults" and "Permuted pairs". Accuracy is represented on the y-axis, and the entities are displayed on the x-axis. Each entity has two bars representing its accuracy under each condition. Error bars are present on top of each bar, indicating the variability or confidence interval.
### Components/Axes
* **X-axis:** Entity - labeled as "Human", "GPT-4", and "Claude 3".
* **Y-axis:** Accuracy - ranging from 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner.
* "Defaults" - represented by a black outline.
* "Permuted pairs" - represented by a light blue fill.
### Detailed Analysis
The chart consists of six bars, grouped by entity. Each entity has a bar for "Defaults" and a bar for "Permuted pairs". Error bars are shown on top of each bar.
* **Human:**
* "Defaults": Approximately 0.86.
* "Permuted pairs": Approximately 0.83.
* **GPT-4:**
* "Defaults": Approximately 0.78.
* "Permuted pairs": Approximately 0.56.
* **Claude 3:**
* "Defaults": Approximately 0.82.
* "Permuted pairs": Approximately 0.54.
The error bars indicate the following approximate ranges:
* **Human Defaults:** 0.82 - 0.90
* **Human Permuted Pairs:** 0.79 - 0.87
* **GPT-4 Defaults:** 0.74 - 0.82
* **GPT-4 Permuted Pairs:** 0.52 - 0.60
* **Claude 3 Defaults:** 0.78 - 0.86
* **Claude 3 Permuted Pairs:** 0.50 - 0.58
### Key Observations
* Humans exhibit the highest accuracy in both conditions ("Defaults" and "Permuted pairs").
* The accuracy of both GPT-4 and Claude 3 decreases significantly when switching from "Defaults" to "Permuted pairs".
* GPT-4 and Claude 3 have similar accuracy under the "Permuted pairs" condition.
* The error bars suggest that the accuracy of "Defaults" is more consistent than "Permuted pairs" for all three entities.
### Interpretation
The data suggests that humans outperform both GPT-4 and Claude 3 in this accuracy comparison. The significant drop in accuracy for GPT-4 and Claude 3 when presented with "Permuted pairs" indicates that their performance is sensitive to the order or arrangement of the input data. This could imply that these models rely on positional cues or patterns that are disrupted by the permutation process. The relatively stable performance of humans suggests a greater ability to generalize and maintain accuracy even when the input is altered. The error bars indicate that the human performance is more consistent, while the AI models show more variability. This could be due to the inherent stochasticity of the models or the complexity of the task. The fact that GPT-4 and Claude 3 perform similarly under the "Permuted pairs" condition suggests that they may share similar vulnerabilities to this type of manipulation.