## Bar Chart: Accuracy Comparison of Human and AI Models Under Default and Permuted Pair Conditions
### Overview
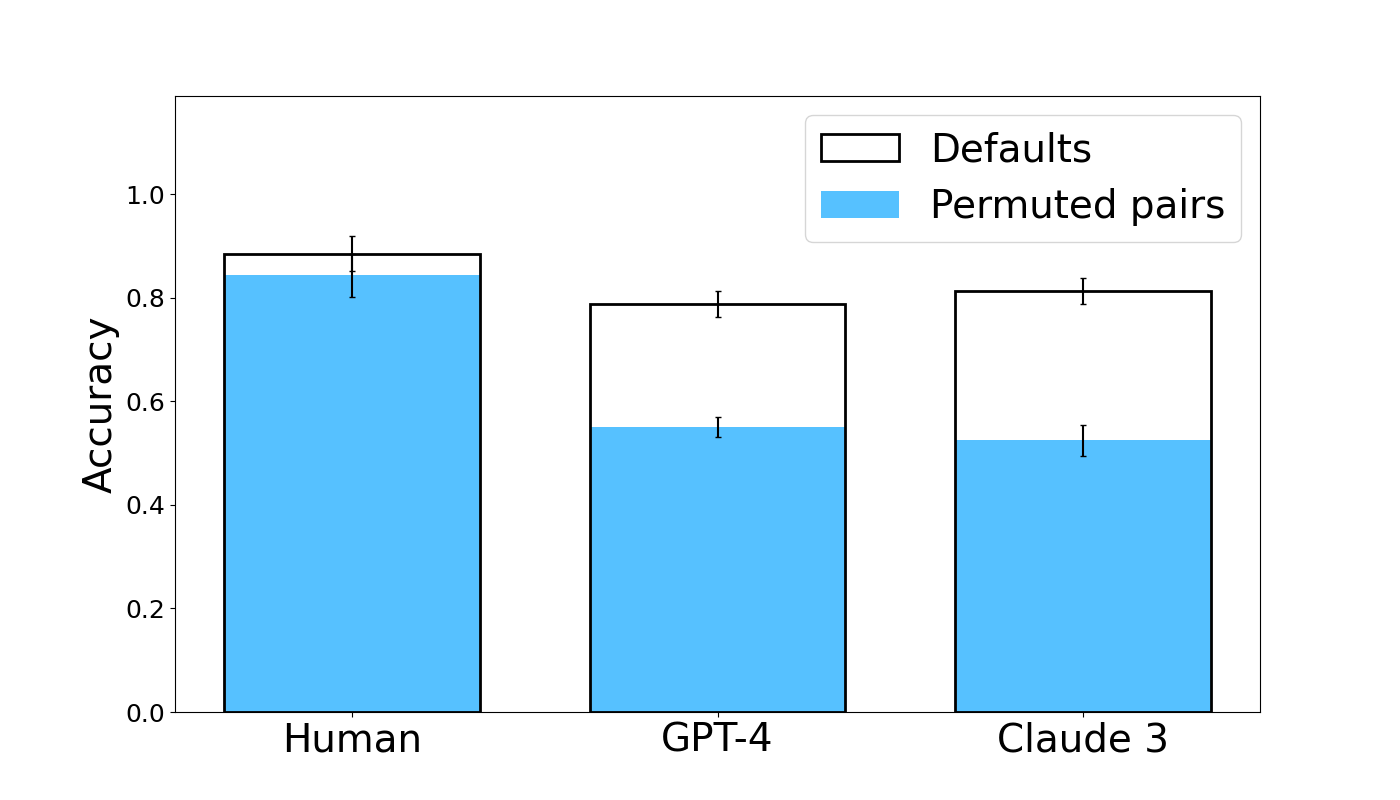
The image is a grouped bar chart comparing the accuracy of three entities—Human, GPT-4, and Claude 3—under two experimental conditions: "Defaults" and "Permuted pairs." The chart visually demonstrates a performance gap between the two conditions for each entity, with a notably larger drop for the AI models.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:** Labeled "Accuracy." The scale runs from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:** Contains three categorical groups: "Human," "GPT-4," and "Claude 3."
* **Legend:** Located in the top-right corner of the plot area.
* A white bar with a black outline represents the "Defaults" condition.
* A solid light blue bar represents the "Permuted pairs" condition.
* **Data Series:** Each of the three x-axis categories has two adjacent bars corresponding to the legend conditions. Each bar is topped with a vertical error bar (black line with horizontal caps).
### Detailed Analysis
**1. Human Group (Leftmost)**
* **Defaults (White Bar):** The top of the bar aligns with an accuracy of approximately **0.88**. The error bar extends from roughly 0.85 to 0.91.
* **Permuted pairs (Blue Bar):** The top of the bar aligns with an accuracy of approximately **0.84**. The error bar extends from roughly 0.81 to 0.87.
* **Trend:** The accuracy for "Permuted pairs" is slightly lower than for "Defaults," but the difference is small, and the error bars overlap significantly.
**2. GPT-4 Group (Center)**
* **Defaults (White Bar):** The top of the bar aligns with an accuracy of approximately **0.79**. The error bar extends from roughly 0.77 to 0.81.
* **Permuted pairs (Blue Bar):** The top of the bar aligns with an accuracy of approximately **0.55**. The error bar extends from roughly 0.53 to 0.57.
* **Trend:** There is a substantial drop in accuracy from the "Defaults" to the "Permuted pairs" condition. The error bars for the two conditions do not overlap.
**3. Claude 3 Group (Rightmost)**
* **Defaults (White Bar):** The top of the bar aligns with an accuracy of approximately **0.81**. The error bar extends from roughly 0.79 to 0.83.
* **Permuted pairs (Blue Bar):** The top of the bar aligns with an accuracy of approximately **0.52**. The error bar extends from roughly 0.50 to 0.54.
* **Trend:** Similar to GPT-4, there is a large drop in accuracy from "Defaults" to "Permuted pairs." The error bars for the two conditions do not overlap.
### Key Observations
1. **Condition Effect:** For all three entities, accuracy is higher in the "Defaults" condition than in the "Permuted pairs" condition.
2. **Magnitude of Effect:** The negative impact of permutation is dramatically larger for the AI models (GPT-4 and Claude 3) than for Humans. The drop for Humans is approximately 0.04 accuracy points, while the drops for GPT-4 and Claude 3 are approximately 0.24 and 0.29 points, respectively.
3. **AI Model Comparison:** Under the "Defaults" condition, Claude 3 (≈0.81) performs slightly better than GPT-4 (≈0.79). Under the "Permuted pairs" condition, their performance is very similar (GPT-4 ≈0.55, Claude 3 ≈0.52), with both falling to near or just above chance level (0.5).
4. **Human Performance:** Human accuracy remains high and relatively stable across both conditions, staying above 0.8.
### Interpretation
This chart presents evidence from a cognitive or linguistic experiment testing robustness to permutation. The "Defaults" condition likely represents a standard, expected, or natural pairing of items (e.g., words, concepts, images). The "Permuted pairs" condition involves randomly shuffling these pairings.
The data suggests that **human performance is largely resilient to this permutation**, indicating that human understanding or task completion does not rely heavily on the specific, default pairings tested. In contrast, **both GPT-4 and Claude 3 show a severe performance degradation when the default pairings are disrupted**. This implies that these AI models may be leveraging statistical associations or patterns inherent in the default data structure to a much greater degree. When those structures are broken (permuted), their ability to perform the task collapses toward random guessing.
The key takeaway is a qualitative difference in processing: humans appear to use a more flexible, conceptual understanding that survives recombination, while the AI models' performance is more contingent on the specific, learned configurations of the input data. This has implications for evaluating the robustness and generalization capabilities of large language models.