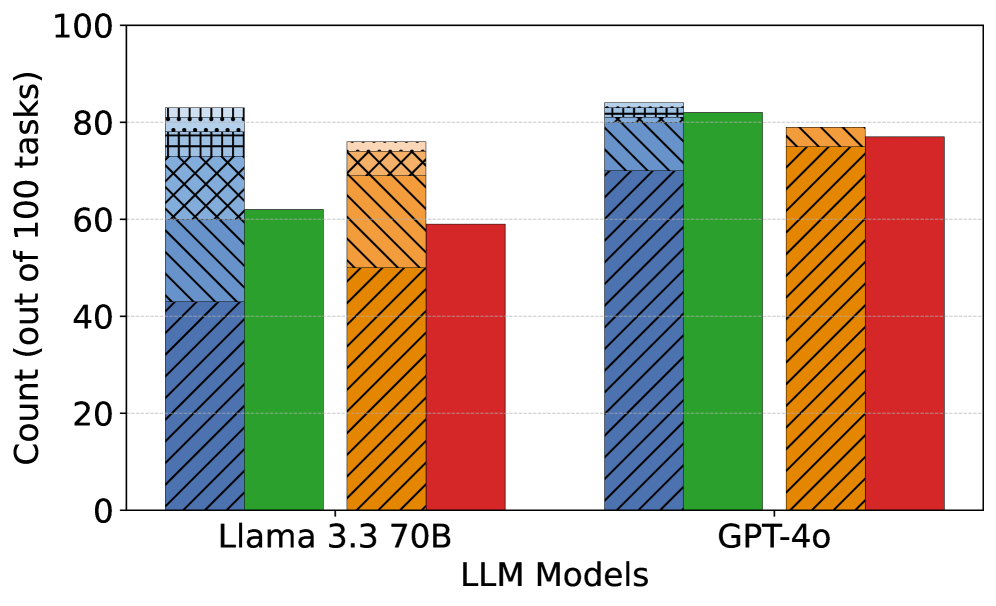
## Bar Chart: Task Performance Comparison of LLM Models
### Overview
The chart compares the task performance of two large language models (LLMs), **Llama 3.3 70B** and **GPT-4o**, across four categories: **Correct**, **Partially Correct**, **Incorrect**, and **Unknown**. The y-axis represents the count of tasks (out of 100), while the x-axis lists the models. Each category is represented by a distinct color and pattern.
### Components/Axes
- **X-axis (Models)**:
- Llama 3.3 70B (left)
- GPT-4o (right)
- **Y-axis (Count)**:
- Labeled "Count (out of 100 tasks)" with increments from 0 to 100.
- **Legend (Right)**:
- **Correct**: Blue (solid) with diagonal stripes.
- **Partially Correct**: Green (solid).
- **Incorrect**: Orange (solid) with diagonal stripes.
- **Unknown**: Red (solid).
### Detailed Analysis
#### Llama 3.3 70B
- **Correct**: ~60 tasks (blue diagonal stripes).
- **Partially Correct**: ~20 tasks (green).
- **Incorrect**: ~15 tasks (orange diagonal stripes).
- **Unknown**: ~5 tasks (red).
#### GPT-4o
- **Correct**: ~80 tasks (blue diagonal stripes).
- **Partially Correct**: ~15 tasks (green).
- **Incorrect**: ~3 tasks (orange diagonal stripes).
- **Unknown**: ~2 tasks (red).
### Key Observations
1. **GPT-4o outperforms Llama 3.3 70B** in task accuracy, with a significantly higher count of **Correct** tasks (~80 vs. ~60).
2. **Unknown tasks** are minimal for both models, but GPT-4o has fewer (~2 vs. ~5).
3. **Partially Correct** tasks are higher for Llama 3.3 70B (~20 vs. ~15), suggesting it may handle ambiguous tasks better but with lower precision.
4. **Incorrect tasks** are notably lower for GPT-4o (~3 vs. ~15), indicating superior reliability.
### Interpretation
The data demonstrates that **GPT-4o** achieves higher task completion accuracy and reliability compared to **Llama 3.3 70B**. While Llama 3.3 70B shows a higher proportion of **Partially Correct** tasks, this does not compensate for its lower **Correct** task count. The minimal **Unknown** tasks for both models suggest robust handling of edge cases, but GPT-4o’s dominance in **Correct** tasks highlights its superior performance. This aligns with expectations for advanced LLMs, where GPT-4o’s architecture likely enables more precise task execution.