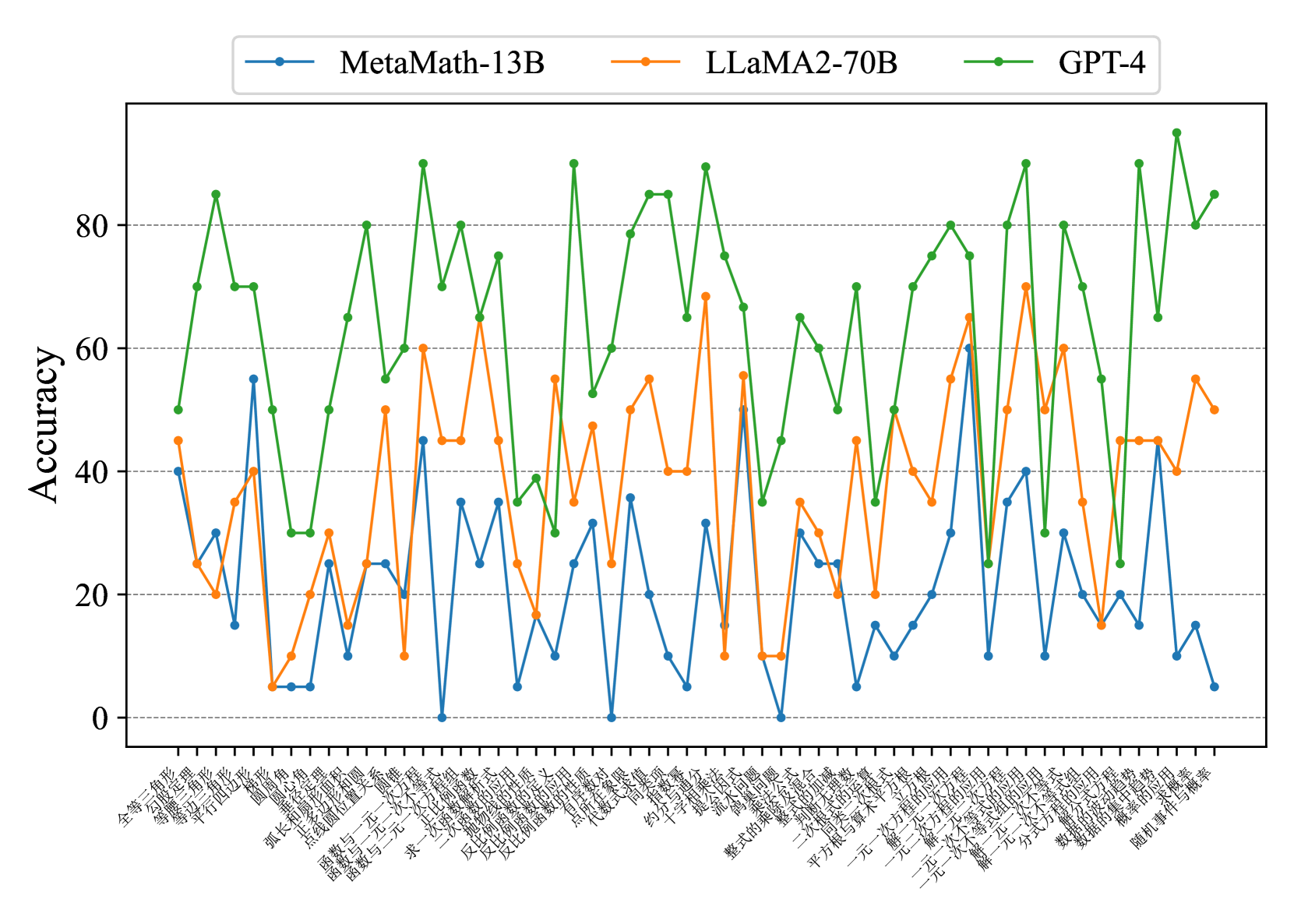
## Line Chart: Model Accuracy Comparison
### Overview
The image is a line chart comparing the accuracy of three language models: MetaMath-13B, LLaMA2-70B, and GPT-4, across a series of mathematical problems. The x-axis represents different problem types (labeled in Chinese), and the y-axis represents accuracy, ranging from 0 to 80.
### Components/Axes
* **Title:** None visible.
* **X-axis:** Represents different mathematical problem types, labeled in Chinese. The labels are closely spaced and difficult to read individually.
* **Y-axis:** "Accuracy", ranging from 0 to 80 in increments of 20. Horizontal gridlines are present at each increment.
* **Legend:** Located at the top of the chart.
* Blue line: MetaMath-13B
* Orange line: LLaMA2-70B
* Green line: GPT-4
### Detailed Analysis
The chart displays the accuracy of each model across a range of mathematical problems. The x-axis labels are in Chinese, representing different problem types.
Here's a breakdown of each model's performance:
* **MetaMath-13B (Blue):** Generally shows the lowest accuracy among the three models. The accuracy fluctuates significantly across different problem types, ranging from approximately 0 to 60.
* **LLaMA2-70B (Orange):** Shows a moderate level of accuracy, generally higher than MetaMath-13B but lower than GPT-4. The accuracy also fluctuates, ranging from approximately 5 to 65.
* **GPT-4 (Green):** Consistently demonstrates the highest accuracy across most problem types. The accuracy fluctuates, ranging from approximately 30 to 90.
Here are some approximate data points for each model at the beginning and end of the chart:
* **MetaMath-13B:**
* First data point: Accuracy ~40
* Last data point: Accuracy ~10
* **LLaMA2-70B:**
* First data point: Accuracy ~45
* Last data point: Accuracy ~55
* **GPT-4:**
* First data point: Accuracy ~50
* Last data point: Accuracy ~90
Here is a transcription of the x-axis labels, along with their English translations:
| Chinese Label | Approximate English Translation |
|---|---|
| 全等 | Congruence |
| 等腰三角形 | Isosceles triangle |
| 等边三角形 | Equilateral triangle |
| 平行四边形 | Parallelogram |
| 弧长 | Arc length |
| 圆锥 | Cone |
| 函数与一次函数 | Function and linear function |
| 函数与二次函数 | Function and quadratic function |
| 反比例函数 | Inverse proportional function |
| 整式的加减 | Addition and subtraction of polynomials |
| 一元一次方程 | Linear equation in one variable |
| 平方根 | Square root |
| 用平方根解一元二次方程 | Solving quadratic equations in one variable using square roots |
| 用公式法解一元二次方程 | Solving quadratic equations in one variable using the quadratic formula |
| 用因式分解法解一元二次方程 | Solving quadratic equations in one variable by factoring |
| 一元二次方程的应用 | Application of quadratic equations in one variable |
| 一元一次不等式 | Linear inequality in one variable |
| 一元一次不等式的应用 | Application of linear inequalities in one variable |
| 随机事件与概率 | Random events and probability |
### Key Observations
* GPT-4 consistently outperforms MetaMath-13B and LLaMA2-70B across the majority of problem types.
* MetaMath-13B generally has the lowest accuracy.
* All three models exhibit significant fluctuations in accuracy depending on the problem type.
* The performance gap between GPT-4 and the other two models is substantial.
### Interpretation
The data suggests that GPT-4 is significantly more proficient at solving the mathematical problems represented on the x-axis compared to MetaMath-13B and LLaMA2-70B. The fluctuations in accuracy across different problem types indicate that each model has strengths and weaknesses in specific areas of mathematics. The consistent underperformance of MetaMath-13B suggests it may require further training or optimization to achieve comparable accuracy to the other models. The chart highlights the varying capabilities of different language models in tackling mathematical reasoning tasks.