\n
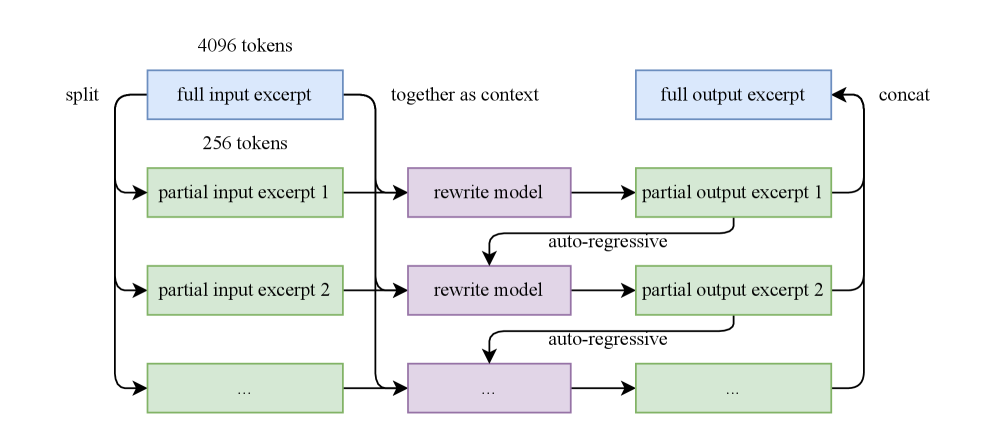
## Diagram: Long-Context Language Model Processing Flow
### Overview
The image depicts a diagram illustrating the process of handling long input sequences (4096 tokens) in a language model. The input is split into smaller excerpts, processed by a "rewrite model", and then concatenated to produce the final output. The process appears iterative, with multiple input excerpts being processed in parallel.
### Components/Axes
The diagram consists of rectangular blocks representing processing steps and arrows indicating the flow of data. Key components and labels include:
* **"split"**: The initial step of dividing the input.
* **"full input excerpt"**: Represents the complete input sequence.
* **"4096 tokens"**: Indicates the total length of the input sequence.
* **"256 tokens"**: Indicates the length of each partial input excerpt.
* **"partial input excerpt 1", "partial input excerpt 2", "...":** Represents individual segments of the input.
* **"rewrite model"**: A processing unit that transforms input excerpts.
* **"auto-regressive"**: Indicates the nature of the output generation process.
* **"partial output excerpt 1", "partial output excerpt 2", "...":** Represents individual segments of the output.
* **"full output excerpt"**: Represents the complete output sequence.
* **"concat"**: The final step of combining the output excerpts.
* **"together as context"**: Indicates the combination of input excerpts for processing.
### Detailed Analysis or Content Details
The diagram shows a process that begins with a 4096-token input. This input is split into excerpts of 256 tokens each. Multiple partial input excerpts are then fed into a "rewrite model". The output of the rewrite model is then processed in an "auto-regressive" manner, generating partial output excerpts. These partial output excerpts are finally concatenated ("concat") to form the full output excerpt. The diagram suggests this process is repeated iteratively, as indicated by the "...".
The flow can be summarized as follows:
1. **Input Split:** 4096 tokens -> Multiple 256-token excerpts.
2. **Rewrite & Auto-regressive Generation:** Each excerpt is processed by the "rewrite model" and then generates a partial output excerpt using an auto-regressive process.
3. **Output Concatenation:** The partial output excerpts are concatenated to form the final output.
### Key Observations
* The diagram highlights a strategy for handling long input sequences by breaking them down into smaller, manageable chunks.
* The "rewrite model" suggests a transformation or adaptation of the input excerpts before output generation.
* The auto-regressive nature of the output generation implies that each output token is generated based on the preceding tokens.
* The iterative nature of the process, indicated by the ellipsis ("..."), suggests that the input can be arbitrarily long.
### Interpretation
This diagram illustrates a technique for processing long sequences in language models, likely to overcome limitations in context window size. By splitting the input into smaller excerpts and processing them individually, the model can effectively handle inputs that exceed its maximum context length. The "rewrite model" likely plays a crucial role in maintaining coherence and consistency across the different excerpts. The auto-regressive generation ensures that the output is generated in a sequential and contextually relevant manner. The concatenation step combines the outputs from each excerpt to produce the final result. This approach is a common strategy for dealing with long-form text generation or processing tasks where the entire input cannot fit into the model's context window at once. The diagram doesn't provide specific details about the "rewrite model" or the auto-regressive process, but it clearly outlines the overall architecture and flow of the system.