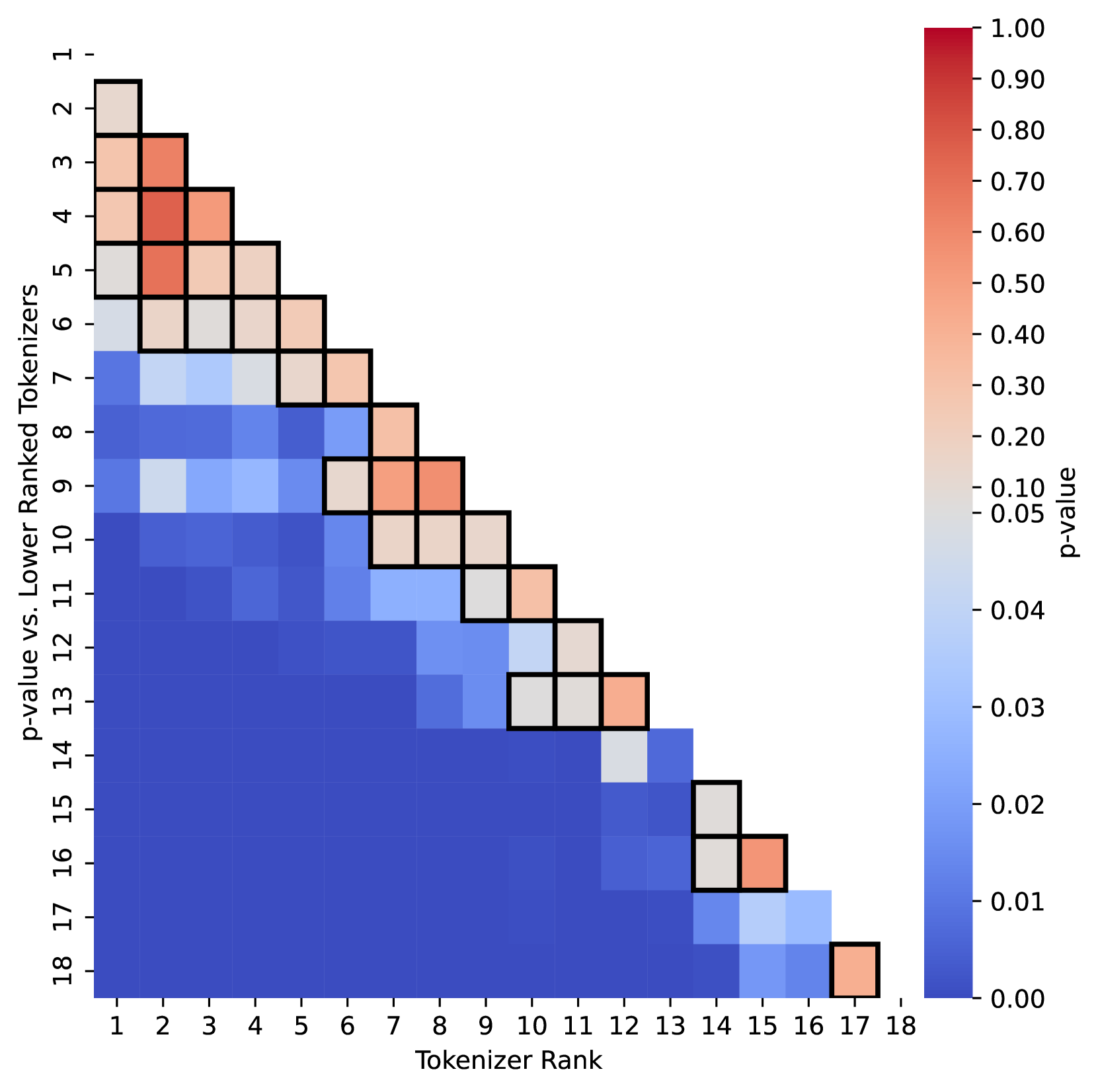
## Heatmap: P-value Comparison of Tokenizers
### Overview
The image is a heatmap displaying the p-values resulting from a comparison of different tokenizers. The heatmap is triangular, showing pairwise comparisons between tokenizers ranked from 1 to 18. The color intensity represents the p-value, ranging from blue (low p-value) to red (high p-value). The heatmap is only filled in the lower triangle.
### Components/Axes
* **X-axis:** "Tokenizer Rank" ranging from 1 to 18.
* **Y-axis:** "p-value vs. Lower Ranked Tokenizers" ranging from 1 to 18.
* **Colorbar (right side):** "p-value" ranging from 0.00 (blue) to 1.00 (red). The colorbar has the following markers: 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.10, 0.20, 0.30, 0.40, 0.50, 0.60, 0.70, 0.80, 0.90, 1.00.
### Detailed Analysis
The heatmap is a lower triangular matrix, meaning only the comparisons where the y-axis tokenizer rank is greater than or equal to the x-axis tokenizer rank are shown. Each cell represents the p-value of comparing the tokenizer on the y-axis to the tokenizer on the x-axis.
Here's a breakdown of the p-values for some specific tokenizer comparisons:
* **Tokenizer 1 vs. Tokenizer 2:** p-value is approximately 0.80 (red).
* **Tokenizer 1 vs. Tokenizer 3:** p-value is approximately 0.70 (red).
* **Tokenizer 1 vs. Tokenizer 4:** p-value is approximately 0.90 (red).
* **Tokenizer 1 vs. Tokenizer 5:** p-value is approximately 0.10 (light gray).
* **Tokenizer 1 vs. Tokenizer 6:** p-value is approximately 0.10 (light gray).
* **Tokenizer 1 vs. Tokenizer 7:** p-value is approximately 0.03 (light blue).
* **Tokenizer 1 vs. Tokenizer 8:** p-value is approximately 0.02 (blue).
* **Tokenizer 1 vs. Tokenizer 9:** p-value is approximately 0.10 (light gray).
* **Tokenizer 2 vs. Tokenizer 3:** p-value is approximately 0.70 (red).
* **Tokenizer 2 vs. Tokenizer 4:** p-value is approximately 0.80 (red).
* **Tokenizer 2 vs. Tokenizer 5:** p-value is approximately 0.60 (red).
* **Tokenizer 2 vs. Tokenizer 6:** p-value is approximately 0.10 (light gray).
* **Tokenizer 2 vs. Tokenizer 7:** p-value is approximately 0.04 (light blue).
* **Tokenizer 2 vs. Tokenizer 8:** p-value is approximately 0.03 (light blue).
* **Tokenizer 2 vs. Tokenizer 9:** p-value is approximately 0.02 (blue).
* **Tokenizer 3 vs. Tokenizer 4:** p-value is approximately 0.90 (red).
* **Tokenizer 3 vs. Tokenizer 5:** p-value is approximately 0.10 (light gray).
* **Tokenizer 3 vs. Tokenizer 6:** p-value is approximately 0.20 (light orange).
* **Tokenizer 3 vs. Tokenizer 7:** p-value is approximately 0.04 (light blue).
* **Tokenizer 3 vs. Tokenizer 3:** p-value is approximately 0.70 (red).
* **Tokenizer 4 vs. Tokenizer 4:** p-value is approximately 0.90 (red).
* **Tokenizer 4 vs. Tokenizer 5:** p-value is approximately 0.70 (red).
* **Tokenizer 4 vs. Tokenizer 6:** p-value is approximately 0.20 (light orange).
* **Tokenizer 4 vs. Tokenizer 7:** p-value is approximately 0.03 (light blue).
* **Tokenizer 5 vs. Tokenizer 5:** p-value is approximately 0.10 (light gray).
* **Tokenizer 5 vs. Tokenizer 6:** p-value is approximately 0.10 (light gray).
* **Tokenizer 5 vs. Tokenizer 7:** p-value is approximately 0.02 (blue).
* **Tokenizer 6 vs. Tokenizer 6:** p-value is approximately 0.10 (light gray).
* **Tokenizer 6 vs. Tokenizer 7:** p-value is approximately 0.02 (blue).
* **Tokenizer 7 vs. Tokenizer 7:** p-value is approximately 0.70 (red).
* **Tokenizer 8 vs. Tokenizer 8:** p-value is approximately 0.03 (light blue).
* **Tokenizer 9 vs. Tokenizer 9:** p-value is approximately 0.70 (red).
* **Tokenizer 10 vs. Tokenizer 10:** p-value is approximately 0.10 (light gray).
* **Tokenizer 11 vs. Tokenizer 11:** p-value is approximately 0.10 (light gray).
* **Tokenizer 12 vs. Tokenizer 12:** p-value is approximately 0.70 (red).
* **Tokenizer 13 vs. Tokenizer 13:** p-value is approximately 0.05 (light gray).
* **Tokenizer 14 vs. Tokenizer 14:** p-value is approximately 0.10 (light gray).
* **Tokenizer 15 vs. Tokenizer 15:** p-value is approximately 0.70 (red).
* **Tokenizer 16 vs. Tokenizer 16:** p-value is approximately 0.05 (light gray).
* **Tokenizer 17 vs. Tokenizer 17:** p-value is approximately 0.70 (red).
* **Tokenizer 18 vs. Tokenizer 18:** p-value is approximately 0.00 (blue).
### Key Observations
* The top-left portion of the heatmap (comparing lower-ranked tokenizers) generally shows higher p-values (red/orange), indicating less significant differences between those tokenizers.
* The bottom-left portion of the heatmap (comparing higher-ranked tokenizers to lower-ranked ones) generally shows lower p-values (blue), indicating more significant differences.
* There are some exceptions to the general trend, with some cells showing unexpected p-values.
### Interpretation
The heatmap visualizes the statistical significance of differences between various tokenizers. Lower p-values suggest that the tokenizers being compared produce significantly different results. The general trend suggests that higher-ranked tokenizers tend to perform differently from lower-ranked ones, while lower-ranked tokenizers are more similar to each other. The specific p-values can be used to identify which tokenizers are statistically different and to guide the selection of appropriate tokenizers for specific tasks. The high p-values along the diagonal are expected, as they represent the comparison of a tokenizer with itself.