## Charts: Execution Time and Memory Comparison of Attention Mechanisms
### Overview
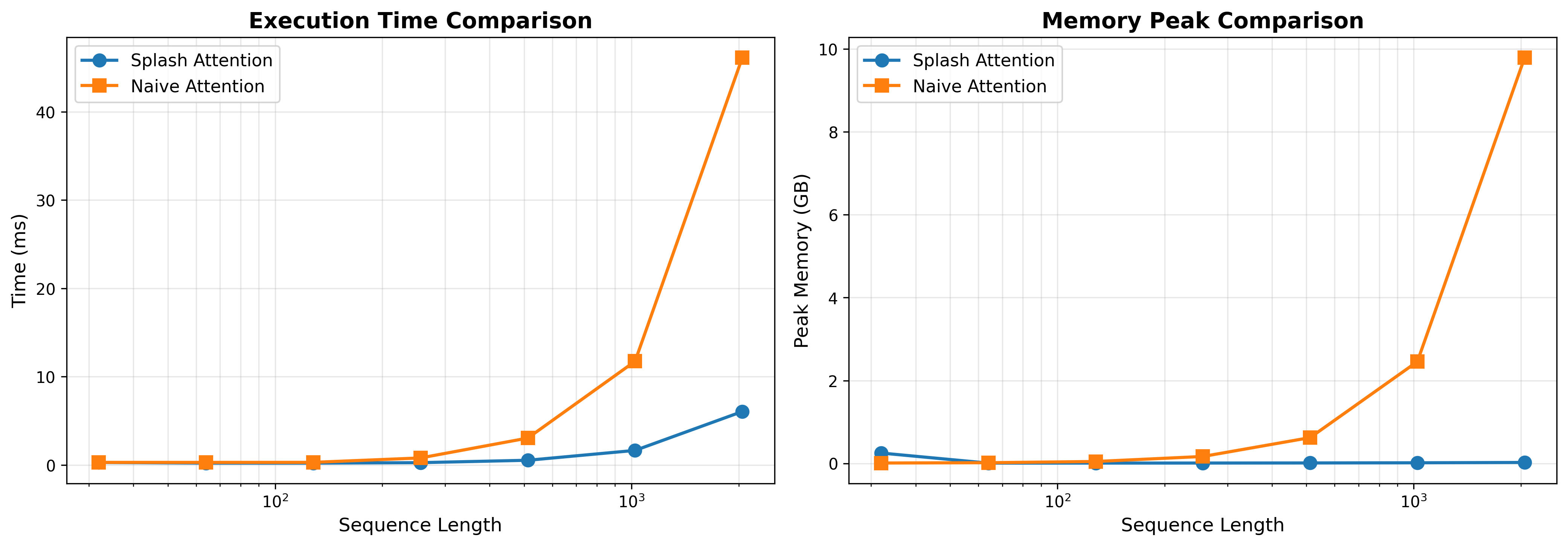
The image presents two charts side-by-side, comparing the performance of "Splash Attention" and "Naive Attention" mechanisms. The left chart shows execution time in milliseconds (ms) versus sequence length, while the right chart displays peak memory usage in gigabytes (GB) against sequence length. Both charts use a logarithmic scale for the sequence length axis.
### Components/Axes
**Chart 1: Execution Time Comparison**
* **Title:** Execution Time Comparison
* **X-axis:** Sequence Length (logarithmic scale, markers at 10⁰, 10¹, 10², 10³)
* **Y-axis:** Time (ms) (scale from 0 to 40)
* **Legend:**
* Splash Attention (Blue line with circle markers)
* Naive Attention (Orange line with square markers)
**Chart 2: Memory Peak Comparison**
* **Title:** Memory Peak Comparison
* **X-axis:** Sequence Length (logarithmic scale, markers at 10⁰, 10¹, 10², 10³)
* **Y-axis:** Peak Memory (GB) (scale from 0 to 10)
* **Legend:**
* Splash Attention (Blue line with circle markers)
* Naive Attention (Orange line with square markers)
### Detailed Analysis or Content Details
**Chart 1: Execution Time Comparison**
* **Splash Attention (Blue):** The line starts at approximately 0.5 ms at a sequence length of 10⁰. It increases gradually to around 2.5 ms at 10¹, then to approximately 6 ms at 10², and finally reaches about 8 ms at 10³. The trend is generally upward, but the slope increases significantly at higher sequence lengths.
* **Naive Attention (Orange):** The line begins at approximately 0.7 ms at 10⁰. It remains relatively flat until 10², where it jumps to around 11 ms. At 10³, it increases dramatically to approximately 10 ms. The trend is relatively flat for lower sequence lengths, then increases sharply.
**Chart 2: Memory Peak Comparison**
* **Splash Attention (Blue):** The line starts at approximately 0.1 GB at 10⁰. It remains relatively constant around 0.2 GB up to 10¹. It then increases slightly to around 0.4 GB at 10² and remains around 0.5 GB at 10³. The trend is nearly flat.
* **Naive Attention (Orange):** The line begins at approximately 0.1 GB at 10⁰. It remains relatively flat around 0.2 GB up to 10¹. It then increases to approximately 1.5 GB at 10² and jumps significantly to around 2.5 GB at 10³. The trend is flat for lower sequence lengths, then increases sharply.
### Key Observations
* For both charts, the sequence length is plotted on a logarithmic scale.
* Splash Attention consistently exhibits lower execution time and memory usage compared to Naive Attention, especially at higher sequence lengths.
* The execution time of Naive Attention increases dramatically at sequence lengths of 10² and 10³, while Splash Attention's execution time increases more gradually.
* The memory usage of Naive Attention also increases sharply at sequence lengths of 10² and 10³, while Splash Attention's memory usage remains relatively stable.
* The difference in memory usage between the two attention mechanisms becomes much more pronounced at higher sequence lengths.
### Interpretation
The data suggests that Splash Attention is significantly more scalable and efficient than Naive Attention, particularly when dealing with longer sequences. The logarithmic scale on the x-axis highlights the exponential growth in computational cost and memory requirements for Naive Attention as the sequence length increases. Splash Attention demonstrates a more linear increase in both execution time and memory usage, indicating a more efficient algorithm.
The sharp increase in Naive Attention's performance metrics at sequence lengths of 10² and 10³ could indicate a bottleneck or a computational complexity that grows rapidly with sequence length. This could be due to the quadratic complexity of the naive attention mechanism. Splash Attention, likely employing a more optimized approach, avoids this steep increase.
The consistent low memory usage of Splash Attention is a key advantage, as memory constraints often limit the size of sequences that can be processed. This makes Splash Attention a more practical choice for applications involving long sequences, such as natural language processing or long-range dependencies in time series data. The data strongly suggests that Splash Attention is a superior choice for handling long sequences due to its scalability and efficiency.