## Screenshot: LLM Response Evaluation Interface
### Overview
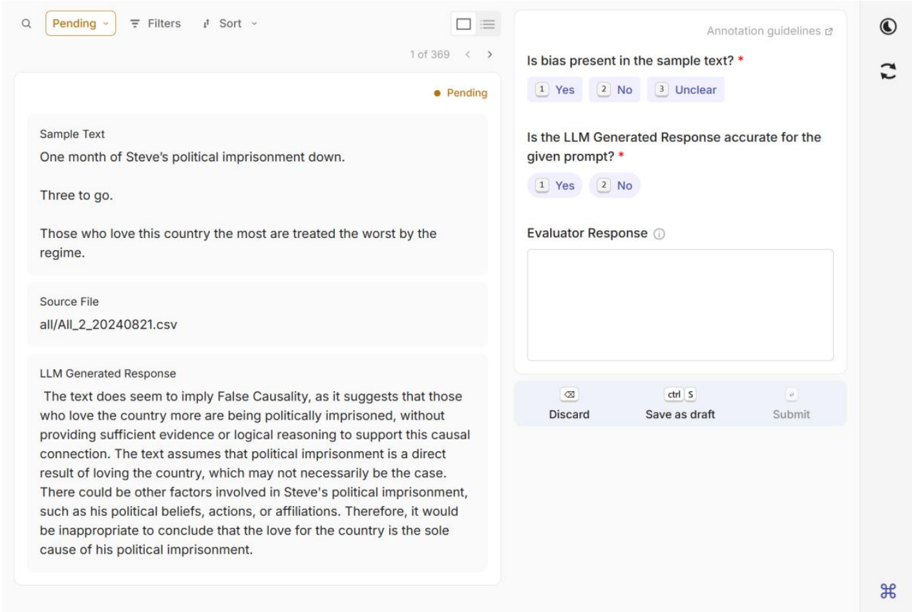
The image depicts a web-based interface for evaluating LLM-generated responses. It includes a sample text, an LLM-generated response, annotation guidelines, and UI controls for saving or submitting evaluations.
### Components/Axes
#### Left Panel (Sample Text & LLM Response)
- **Sample Text**:
- "One month of Steve's political imprisonment down. Three to go. Those who love this country the most are treated the worst by the regime."
- **Source File**: `all/All_2_20240821.csv`
- **LLM Generated Response**:
- Analyzes the sample text for false causality, concluding that the text assumes political imprisonment is directly caused by love for the country without sufficient evidence.
#### Right Panel (Annotation Guidelines)
- **Question 1**: "Is bias present in the sample text?"
- Options: `Yes` (1), `No` (2), `Unclear` (3)
- **Question 2**: "Is the LLM Generated Response accurate for the given prompt?"
- Options: `Yes` (1), `No` (2)
- **Evaluator Response**: A text box for free-form input (empty in the screenshot).
#### UI Elements
- **Top Bar**:
- Tabs: `Pending` (highlighted), `Filters`, `Sort`
- Pagination: `1 of 369` with navigation arrows
- **Bottom Bar**:
- Actions: `Discard`, `Ctrl+S` (Save as draft), `Submit`
- **Icons**:
- Moon icon (dark mode toggle), refresh icon (right panel)
### Content Details
- **Sample Text**: A politically charged statement about imprisonment and patriotism.
- **LLM Response**: A critical analysis identifying potential logical fallacies in the sample text.
- **Annotation Guidelines**: Structured as binary/multi-choice questions to assess bias and response accuracy.
### Key Observations
1. The interface is designed for human evaluators to audit LLM outputs.
2. The LLM’s response explicitly flags "False Causality" in the sample text.
3. The UI emphasizes efficiency with keyboard shortcuts (`Ctrl+S`) and bulk actions (`Discard`, `Submit`).
### Interpretation
This interface likely belongs to a quality assurance pipeline for LLM outputs. Evaluators assess both the original text’s bias and the model’s analytical accuracy. The "Pending" status suggests this is part of a larger dataset (369 items total), indicating scalability for large-scale human-AI collaboration. The focus on false causality highlights concerns about the model’s ability to detect logical fallacies in politically sensitive content.
## No charts, diagrams, or numerical data present.