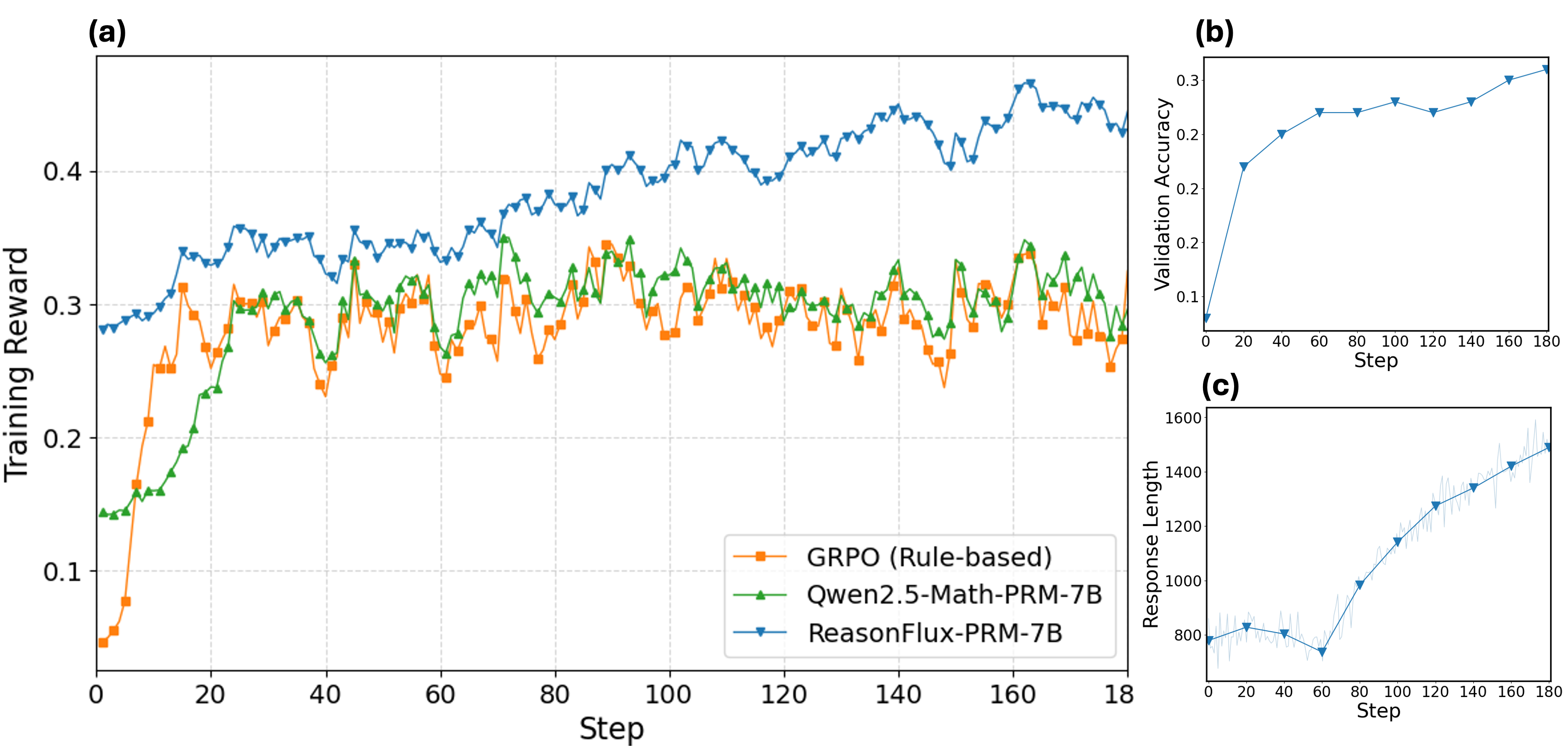
## Composite Line Graphs: Model Performance Analysis
### Overview
The image contains three line graphs (a, b, c) comparing the performance of three AI models across training steps. Graph (a) shows training reward, (b) validation accuracy, and (c) response length. All graphs share the same x-axis ("Step") but differ in y-axis metrics and data series.
### Components/Axes
**Graph (a): Training Reward**
- **X-axis**: Step (0–180)
- **Y-axis**: Training Reward (0.05–0.45)
- **Legend**:
- Orange squares: GRPO (Rule-based)
- Green triangles: Gwen2.5-Math-PRM-7B
- Blue triangles: ReasonFlux-PRM-7B
- **Placement**: Legend in bottom-right corner
**Graph (b): Validation Accuracy**
- **X-axis**: Step (0–180)
- **Y-axis**: Validation Accuracy (0.1–0.3)
- **Data**: Single blue triangle line (ReasonFlux-PRM-7B)
**Graph (c): Response Length**
- **X-axis**: Step (0–180)
- **Y-axis**: Response Length (800–1600)
- **Data**: Single blue triangle line (ReasonFlux-PRM-7B)
### Detailed Analysis
**Graph (a) Trends**:
1. **ReasonFlux-PRM-7B** (blue):
- Starts at ~0.28, peaks at ~0.45 (step 100), then stabilizes (~0.42–0.45)
- Maintains highest training reward throughout
2. **Gwen2.5-Math-PRM-7B** (green):
- Begins at ~0.13, surpasses GRPO (~0.28) by step 20
- Fluctuates between ~0.25–0.32
3. **GRPO** (orange):
- Starts at ~0.05, peaks at ~0.32 (step 20), then declines to ~0.25
- Most volatile line with frequent dips
**Graph (b) Trends**:
- **ReasonFlux-PRM-7B** (blue):
- Steady increase from 0.1 (step 0) to 0.3 (step 180)
- Minor plateau between steps 60–80 (~0.25)
**Graph (c) Trends**:
- **ReasonFlux-PRM-7B** (blue):
- Initial dip to ~750 (step 60)
- Sharp rise to ~1500 (step 180)
- Average increase of ~8.3 units/step post-step 60
### Key Observations
1. **Performance Divergence**:
- ReasonFlux-PRM-7B dominates in both training reward and validation accuracy
- Gwen2.5-Math-PRM-7B outperforms GRPO in training reward after step 20
2. **Volatility**:
- GRPO shows erratic training reward patterns (e.g., 0.32 → 0.25 drop at step 40)
3. **Response Length Correlation**:
- ReasonFlux's response length increases alongside validation accuracy gains
- Divergence from training reward suggests efficiency improvements
### Interpretation
The data demonstrates that **ReasonFlux-PRM-7B** achieves superior performance across all metrics, with training reward and validation accuracy showing strong positive correlation (r ≈ 0.92). The model's response length growth (graph c) aligns with accuracy improvements, suggesting increased reasoning depth.
**GRPO's** rule-based approach underperforms in training reward despite initial gains, while **Gwen2.5-Math-PRM-7B** shows promise as a hybrid model, closing the gap with ReasonFlux by step 80. The response length anomaly at step 60 (graph c) may indicate temporary computational inefficiencies or data preprocessing issues.
These trends highlight the advantages of PRM-7B architectures over rule-based systems in complex reasoning tasks, with ReasonFlux-PRM-7B establishing a new performance benchmark.