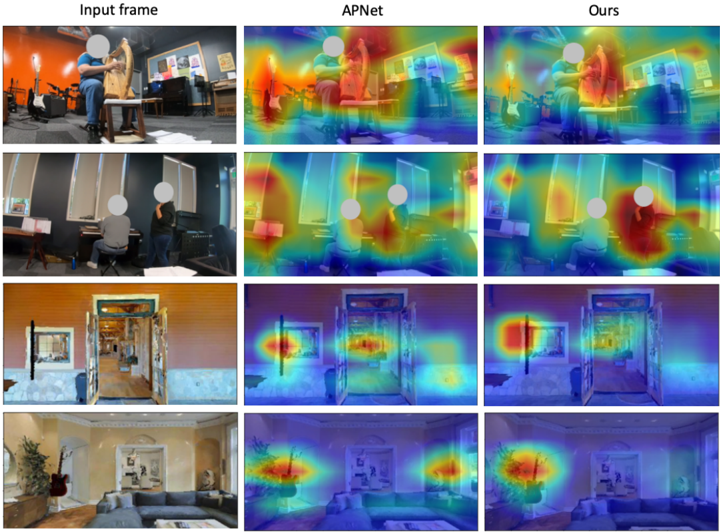
## Image Comparison: Input Frame vs. APNet vs. Ours
### Overview
The image presents a visual comparison of scene understanding between an "Input frame," "APNet," and "Ours." It consists of four rows, each depicting a different scene. The "Input frame" column shows the original image, while the "APNet" and "Ours" columns display heatmaps overlaid on the original images, presumably representing the focus or attention of each method. The heatmaps use a color gradient, with red indicating higher attention and blue indicating lower attention. The faces of people in the images are obscured with gray circles.
### Components/Axes
* **Columns:**
* Input frame
* APNet
* Ours
* **Rows:** Each row represents a different scene.
* Row 1: A person playing a harp in a room with musical instruments.
* Row 2: Two people in a room with a piano and other equipment.
* Row 3: An open doorway leading to another room.
* Row 4: A living room with a couch, guitar, and other furniture.
* **Heatmap Color Gradient:** Red indicates high attention, transitioning through yellow, green, and blue to indicate low attention.
### Detailed Analysis
**Row 1: Harp Player**
* **Input frame:** A person is seated and playing a harp. Guitars and other musical equipment are visible in the background.
* **APNet:** The heatmap shows attention distributed across the person, the harp, and some background elements. The highest attention (red) is focused on the harp and the person's hands.
* **Ours:** The heatmap is similar to APNet, with high attention (red) on the harp and the person's hands. The attention seems slightly more focused on the harp itself compared to APNet.
**Row 2: Piano Scene**
* **Input frame:** Two people are in a room. One person is seated at a piano, and another is standing nearby.
* **APNet:** The heatmap shows attention focused on the person standing and the piano. The highest attention (red) is on the standing person.
* **Ours:** The heatmap shows attention focused on the person standing and the piano. The highest attention (red) is on the standing person, similar to APNet.
**Row 3: Doorway Scene**
* **Input frame:** An open doorway leads to another room. A mirror is visible on the left wall.
* **APNet:** The heatmap shows high attention (red) focused on the doorway and the mirror.
* **Ours:** The heatmap shows high attention (red) focused on the doorway and the mirror, similar to APNet.
**Row 4: Living Room Scene**
* **Input frame:** A living room with a couch, a guitar leaning against the wall, and other furniture.
* **APNet:** The heatmap shows high attention (red) focused on the guitar and the area around the doorway.
* **Ours:** The heatmap shows high attention (red) focused on the guitar and the area around the doorway, similar to APNet.
### Key Observations
* Both APNet and "Ours" methods generate heatmaps that highlight salient objects and regions in the scenes.
* In most cases, the heatmaps generated by APNet and "Ours" are qualitatively similar, suggesting that both methods attend to similar features.
* The heatmaps tend to focus on objects of interest, such as people, musical instruments, and doorways.
### Interpretation
The image demonstrates a comparison of attention mechanisms between two methods, APNet and "Ours," in various scenes. The heatmaps suggest that both methods are capable of identifying and focusing on relevant objects and regions within the images. The similarity between the heatmaps generated by APNet and "Ours" indicates that both methods have a similar understanding of the scene's important elements. The heatmaps provide a visual representation of the model's focus, which can be useful for understanding how the model makes decisions and for identifying potential areas for improvement.