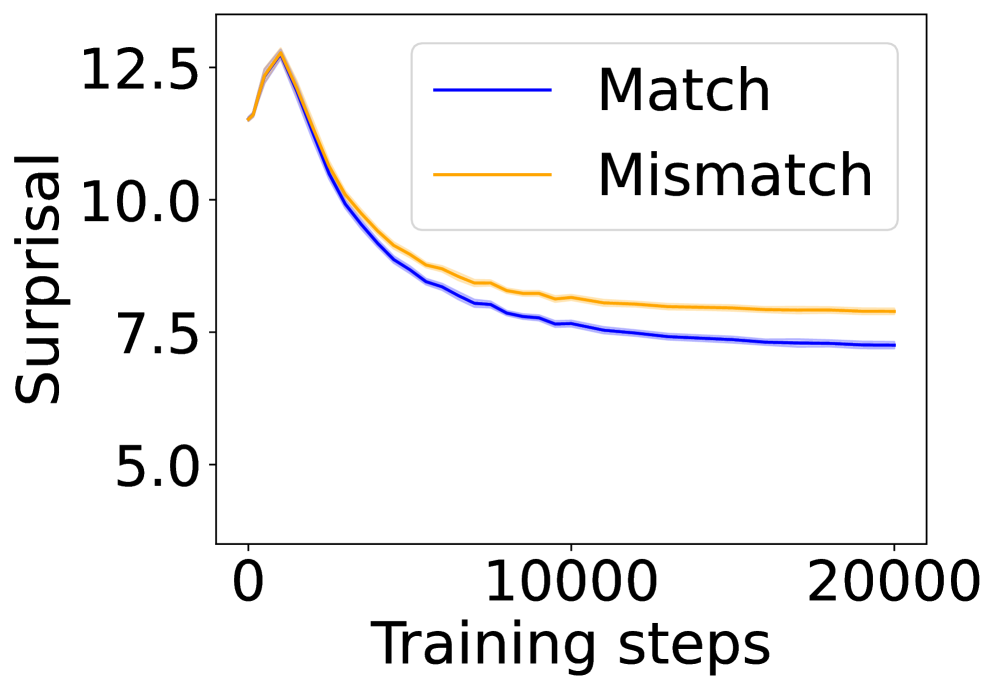
## Line Graph: Surprisal vs Training Steps
### Overview
The graph depicts the relationship between "Surprisal" (y-axis) and "Training steps" (x-axis) for two conditions: "Match" (blue line) and "Mismatch" (orange line). Both lines show a declining trend over 20,000 training steps, with the "Match" condition consistently outperforming the "Mismatch" condition.
### Components/Axes
- **Y-axis (Surprisal)**: Ranges from 5.0 to 12.5 in increments of 2.5.
- **X-axis (Training steps)**: Ranges from 0 to 20,000 in increments of 10,000.
- **Legend**: Located in the top-right corner, with:
- Blue line labeled "Match"
- Orange line labeled "Mismatch"
### Detailed Analysis
1. **Initial Peak (0–2,000 steps)**:
- Both lines start near **12.5 surprisal** at 0 steps.
- The "Match" line (blue) drops sharply to ~10.0 by 2,000 steps.
- The "Mismatch" line (orange) declines more gradually to ~10.5 by 2,000 steps.
2. **Midpoint (2,000–10,000 steps)**:
- "Match" line continues declining to ~8.0 by 10,000 steps.
- "Mismatch" line plateaus slightly above ~8.5 by 10,000 steps.
3. **Final Phase (10,000–20,000 steps)**:
- "Match" line stabilizes near **7.5 surprisal**.
- "Mismatch" line remains flat at ~8.0 surprisal.
### Key Observations
- The "Match" condition achieves a **~40% reduction** in surprisal (from 12.5 to 7.5) over 20,000 steps.
- The "Mismatch" condition shows a **~40% reduction** (from 12.5 to 8.0) but maintains higher surprisal throughout training.
- Both lines exhibit **asymptotic behavior**, suggesting diminishing returns in surprisal reduction after ~10,000 steps.
### Interpretation
The data demonstrates that models trained on "Match" data achieve lower surprisal (better performance) compared to "Mismatch" data. The steeper initial decline in the "Match" line indicates faster adaptation to predictable patterns, while the "Mismatch" line’s plateau suggests persistent uncertainty or noise in the training data. This aligns with principles of information theory, where lower surprisal reflects higher predictability. The divergence between conditions highlights the importance of data quality in model training.