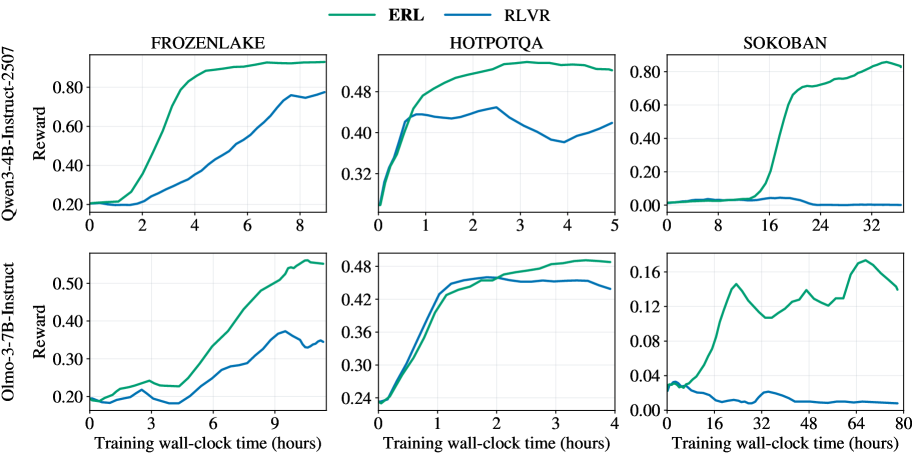
## Line Charts: Reward vs. Training Time for Different Models and Environments
### Overview
The image presents six line charts arranged in a 2x3 grid. Each chart displays the reward achieved by two different models (ERL and RLVR) during training across three different environments (FROZENLAKE, HOTPOTQA, and SOKOBAN). The x-axis represents training wall-clock time in hours, and the y-axis represents the reward. The top row of charts corresponds to the "Qwen3-4B-Instruct-2507" model, while the bottom row corresponds to the "Olmo-3-7B-Instruct" model.
### Components/Axes
* **Title (Top Row):** Qwen3-4B-Instruct-2507
* **Title (Bottom Row):** Olmo-3-7B-Instruct
* **Y-axis Label:** Reward (vertical, rotated 90 degrees counter-clockwise)
* **X-axis Label:** Training wall-clock time (hours)
* **Environments (Top Row, Left to Right):** FROZENLAKE, HOTPOTQA, SOKOBAN
* **Legend (Top, between FROZENLAKE and HOTPOTQA):**
* ERL (Green line)
* RLVR (Blue line)
**Y-Axis Scales:**
* **FROZENLAKE (Top):** 0.20 to 0.80, increments of 0.20
* **HOTPOTQA (Top):** 0.32 to 0.48, increments of 0.08
* **SOKOBAN (Top):** 0.00 to 0.80, increments of 0.20
* **FROZENLAKE (Bottom):** 0.20 to 0.50, increments of 0.10
* **HOTPOTQA (Bottom):** 0.24 to 0.48, increments of 0.08
* **SOKOBAN (Bottom):** 0.00 to 0.16, increments of 0.04
**X-Axis Scales:**
* **FROZENLAKE (Top):** 0 to 8 hours, increments of 2
* **HOTPOTQA (Top):** 0 to 5 hours, increments of 1
* **SOKOBAN (Top):** 0 to 32 hours, increments of 8
* **FROZENLAKE (Bottom):** 0 to 9 hours, increments of 3
* **HOTPOTQA (Bottom):** 0 to 4 hours, increments of 1
* **SOKOBAN (Bottom):** 0 to 80 hours, increments of 16
### Detailed Analysis
**Top Row (Qwen3-4B-Instruct-2507):**
* **FROZENLAKE:**
* ERL (Green): Starts at approximately 0.20, rapidly increases to approximately 0.85 by 4 hours, then plateaus.
* RLVR (Blue): Starts at approximately 0.20, increases more gradually to approximately 0.78 by 8 hours.
* **HOTPOTQA:**
* ERL (Green): Starts at approximately 0.32, increases to approximately 0.48 by 1 hour, then plateaus.
* RLVR (Blue): Starts at approximately 0.32, increases to approximately 0.42 by 1 hour, then fluctuates between 0.40 and 0.44.
* **SOKOBAN:**
* ERL (Green): Starts near 0.00, rapidly increases to approximately 0.75 by 24 hours, then plateaus around 0.82.
* RLVR (Blue): Remains near 0.00 throughout the training period.
**Bottom Row (Olmo-3-7B-Instruct):**
* **FROZENLAKE:**
* ERL (Green): Starts at approximately 0.20, increases to approximately 0.55 by 9 hours.
* RLVR (Blue): Starts at approximately 0.20, increases to approximately 0.38 by 9 hours.
* **HOTPOTQA:**
* ERL (Green): Starts at approximately 0.24, increases to approximately 0.48 by 2 hours, then plateaus.
* RLVR (Blue): Starts at approximately 0.24, increases to approximately 0.46 by 2 hours, then plateaus.
* **SOKOBAN:**
* ERL (Green): Starts near 0.02, peaks at approximately 0.16 around 24 hours, then fluctuates between 0.12 and 0.14.
* RLVR (Blue): Remains near 0.00 throughout the training period.
### Key Observations
* ERL (Green) generally outperforms RLVR (Blue) in terms of reward achieved across all environments and models, except for HOTPOTQA with the Olmo-3-7B-Instruct model where they perform similarly.
* The SOKOBAN environment shows the most significant difference in performance between ERL and RLVR, especially for the Qwen3-4B-Instruct-2507 model.
* The Qwen3-4B-Instruct-2507 model generally achieves higher rewards than the Olmo-3-7B-Instruct model, particularly in the FROZENLAKE and SOKOBAN environments.
* The training time required to reach peak performance varies significantly across environments, with HOTPOTQA generally requiring the least amount of time.
### Interpretation
The data suggests that the ERL model is more effective than the RLVR model in these environments, particularly in the challenging SOKOBAN environment. The Qwen3-4B-Instruct-2507 model appears to be a more capable model overall compared to the Olmo-3-7B-Instruct model, achieving higher rewards in most scenarios. The performance differences between the models and environments highlight the importance of model selection and training strategies for specific tasks. The SOKOBAN environment's stark contrast in performance between ERL and RLVR indicates that ERL may be better suited for tasks requiring long-term planning or complex problem-solving. The relatively quick convergence in HOTPOTQA suggests that this environment is less complex or requires less training to achieve optimal performance.