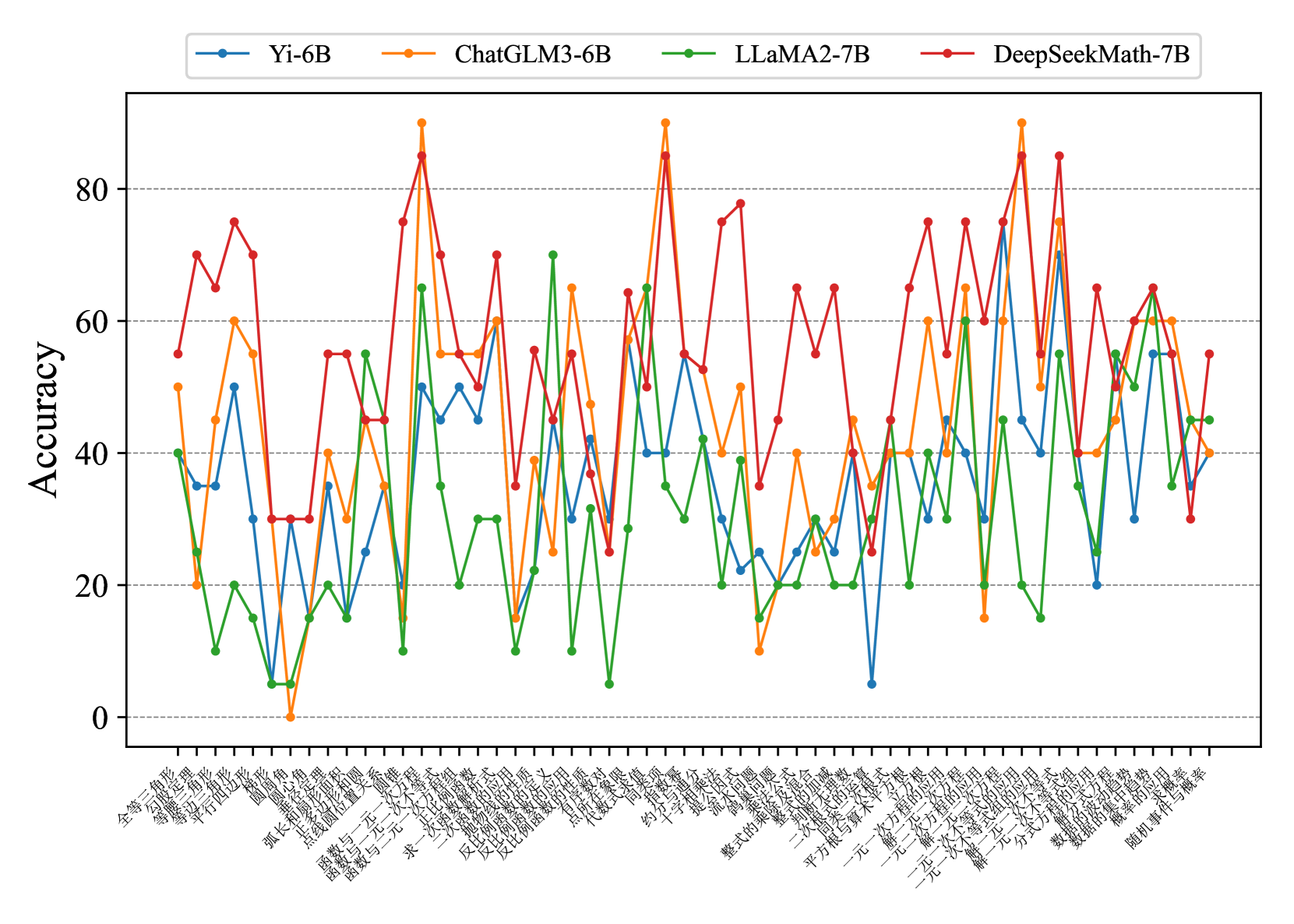
## Line Chart: Model Accuracy on Math Problems
### Overview
The image is a line chart comparing the accuracy of four different language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) on a series of math problems. The x-axis represents different math problem types (in Chinese), and the y-axis represents the accuracy score.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-axis:** Represents different math problem types, labeled in Chinese. The labels are densely packed and rotated for readability.
* **Y-axis:** Represents "Accuracy", ranging from 0 to 80 in increments of 20. Horizontal gridlines are present at each increment.
* **Legend:** Located at the top of the chart.
* Blue line: Yi-6B
* Orange line: ChatGLM3-6B
* Green line: LLaMA2-7B
* Red line: DeepSeekMath-7B
### Detailed Analysis
**X-Axis Labels (Math Problem Types - Chinese with approximate English Translation):**
The x-axis labels are in Chinese. Here's a transcription and approximate translation:
1. 全等三角形 (Quán děng sānjiǎoxíng) - Congruent triangles
2. 等腰三角形 (Děng yāo sānjiǎoxíng) - Isosceles triangle
3. 勾股定理 (Gōu gǔ dìnglǐ) - Pythagorean theorem
4. 平行四边形 (Píngxíng sìbiānxíng) - Parallelogram
5. 函数与一次方程 (Hánshù yǔ yīcì fāngchéng) - Function and linear equation
6. 反比例函数 (Fǎn bǐlì hánshù) - Inverse proportional function
7. 圆 (Yuán) - Circle
8. 弧长与扇形 (Hú cháng yǔ shànxíng) - Arc length and sector
9. 圆锥 (Yuánzhuī) - Cone
10. 点与坐标 (Diǎn yǔ zuòbiāo) - Point and coordinates
11. 函数与一次函数 (Hánshù yǔ yīcì hánshù) - Function and linear function
12. 一次函数 (Yīcì hánshù) - Linear function
13. 关系式 (Guānxì shì) - Relation
14. 求一次函数 (Qiú yīcì hánshù) - Finding a linear function
15. 一元一次方程 (Yī yuán yīcì fāngchéng) - Linear equation in one variable
16. 二次函数 (Èrcì hánshù) - Quadratic function
17. 整式的运算 (Zhěng shì de yùsuàn) - Operations with polynomials
18. 平方根 (Píngfāng gēn) - Square root
19. 一元二次方程 (Yī yuán èrcì fāngchéng) - Quadratic equation in one variable
20. 一元一次不等式 (Yī yuán yīcì bù děngshì) - Linear inequality in one variable
21. 解一元一次方程 (Jiě yī yuán yīcì fāngchéng) - Solving linear equations in one variable
22. 解不等式 (Jiě bù děngshì) - Solving inequalities
23. 分式方程 (Fēnshì fāngchéng) - Fractional equation
24. 整式的加减 (Zhěng shì de jiājiǎn) - Addition and subtraction of polynomials
25. 二次根式 (Èrcì gēnshì) - Quadratic radical
26. 平方根与算术平方根 (Píngfāng gēn yǔ suànshù píngfāng gēn) - Square root and arithmetic square root
27. 一元二次方程的根 (Yī yuán èrcì fāngchéng de gēn) - Roots of a quadratic equation in one variable
28. 概率与频率 (Gàilǜ yǔ pínlǜ) - Probability and frequency
29. 随机事件与概率 (Suíjī shìjiàn yǔ gàilǜ) - Random events and probability
**Data Series Analysis:**
* **Yi-6B (Blue):** The accuracy fluctuates, generally staying between 20 and 60. It shows some peaks and valleys, but no clear upward or downward trend.
* Approximate values: Ranges from ~5 to ~55.
* **ChatGLM3-6B (Orange):** This model shows more variance in accuracy. It has some high peaks, reaching above 80, but also drops to near 0 on some problem types.
* Approximate values: Ranges from ~0 to ~90.
* **LLaMA2-7B (Green):** This model generally has lower accuracy compared to the others, often staying below 40. It also exhibits significant fluctuations.
* Approximate values: Ranges from ~5 to ~70.
* **DeepSeekMath-7B (Red):** This model generally performs the best, with accuracy frequently above 50 and reaching peaks near 90. It also has some dips, but not as severe as ChatGLM3-6B.
* Approximate values: Ranges from ~10 to ~90.
### Key Observations
* DeepSeekMath-7B generally outperforms the other models across most problem types.
* ChatGLM3-6B has the highest variance in performance, with both high peaks and low dips.
* LLaMA2-7B tends to have the lowest accuracy among the four models.
* All models show significant fluctuations in accuracy depending on the specific math problem type.
### Interpretation
The chart demonstrates the varying capabilities of different language models in solving different types of math problems. DeepSeekMath-7B appears to be the most robust model for this specific set of problems, while LLaMA2-7B struggles. The fluctuations in accuracy across problem types suggest that each model has strengths and weaknesses in specific mathematical domains. The performance differences could be attributed to the models' architectures, training data, or specific optimizations for mathematical reasoning. The fact that all models exhibit variance indicates that mathematical reasoning remains a challenging task for these language models, and performance is highly dependent on the specific problem type.