## Pie Chart: Distribution of Text Types by Percentage
### Overview
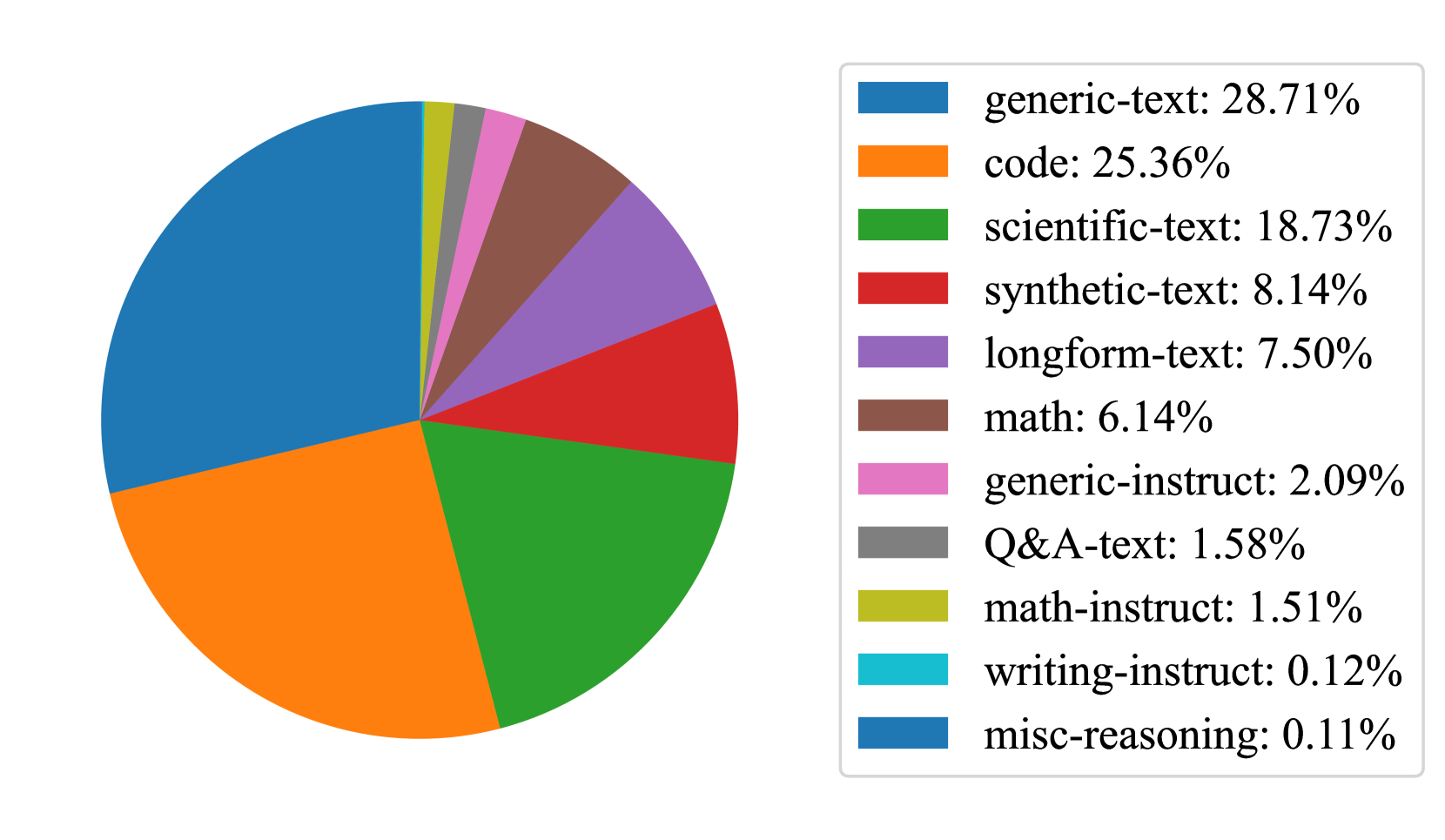
The pie chart illustrates the distribution of text types across a dataset, with percentages indicating the proportion of each category. The largest segments represent "generic-text" (28.71%) and "code" (25.36%), while smaller segments include specialized categories like "math-instruct" (1.51%) and "writing-instruct" (0.12%).
### Components/Axes
- **Legend**: Positioned on the right side of the chart, with colors mapped to text types.
- **Colors and Labels**:
- Blue: generic-text (28.71%)
- Orange: code (25.36%)
- Green: scientific-text (18.73%)
- Red: synthetic-text (8.14%)
- Purple: longform-text (7.50%)
- Brown: math (6.14%)
- Pink: generic-instruct (2.09%)
- Gray: Q&A-text (1.58%)
- Yellow: math-instruct (1.51%)
- Cyan: writing-instruct (0.12%)
- Blue: misc-reasoning (0.11%)
- **Note**: The legend lists two categories ("generic-text" and "misc-reasoning") with the same blue color, which may indicate a labeling error.
- **Pie Segments**: Arranged clockwise, starting with the largest segment ("generic-text") at the top-left.
### Detailed Analysis
1. **Generic-text (Blue)**: 28.71% (largest segment).
2. **Code (Orange)**: 25.36% (second-largest).
3. **Scientific-text (Green)**: 18.73%.
4. **Synthetic-text (Red)**: 8.14%.
5. **Longform-text (Purple)**: 7.50%.
6. **Math (Brown)**: 6.14%.
7. **Generic-instruct (Pink)**: 2.09%.
8. **Q&A-text (Gray)**: 1.58%.
9. **Math-instruct (Yellow)**: 1.51%.
10. **Writing-instruct (Cyan)**: 0.12%.
11. **Misc-reasoning (Blue)**: 0.11%.
### Key Observations
- **Dominance of Generic and Code Texts**: The top two categories account for over 54% of the dataset, suggesting a focus on general and programming-related content.
- **Specialized Categories**: Scientific-text and math-related segments (18.73% and 6.14%, respectively) highlight niche but significant contributions.
- **Minor Segments**: Writing-instruct (0.12%) and misc-reasoning (0.11%) are the smallest, indicating rare or underrepresented text types.
- **Color Discrepancy**: Both "generic-text" and "misc-reasoning" are labeled as blue in the legend, which may cause confusion in interpretation.
### Interpretation
The data suggests a dataset heavily skewed toward general and coding-related text, with specialized domains like scientific and mathematical content forming smaller but notable portions. The near-absence of writing-instruct and misc-reasoning text implies these categories are either underrepresented or excluded from the dataset. The color duplication in the legend (blue for both generic-text and misc-reasoning) risks misinterpretation, as the two categories are visually indistinguishable. This could lead to errors in analysis if not corrected. The chart underscores the importance of clear labeling and color differentiation in data visualization to avoid ambiguity.