## Line Charts: Training Loss Comparison and Distribution Probabilities
### Overview
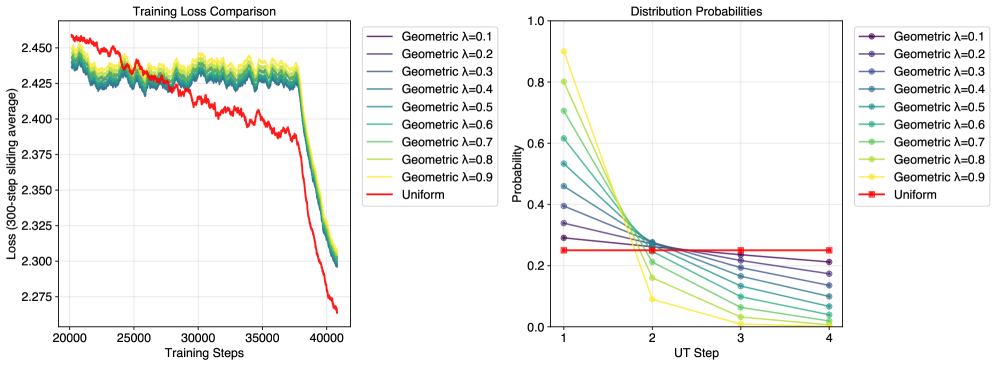
The image contains two line charts comparing training dynamics and distribution probabilities across different hyperparameter settings. The left chart tracks training loss convergence over steps, while the right chart visualizes probability distributions across update (UT) steps for geometric and uniform distributions.
### Components/Axes
**Left Chart (Training Loss Comparison):**
- **X-axis**: Training Steps (20,000 to 40,000)
- **Y-axis**: Loss (300-step sliding average) ranging from 2.275 to 2.450
- **Legend**:
- Geometric distributions (λ=0.1 to λ=0.9) in gradient colors (purple to yellow)
- Uniform distribution (red line)
**Right Chart (Distribution Probabilities):**
- **X-axis**: UT Step (1 to 4)
- **Y-axis**: Probability (0.0 to 1.0)
- **Legend**:
- Geometric distributions (λ=0.1 to λ=0.9) in gradient colors (purple to yellow)
- Uniform distribution (red line)
### Detailed Analysis
**Left Chart Trends:**
1. **Uniform Distribution (Red Line)**:
- Starts at ~2.45 loss at 20,000 steps
- Gradually decreases to ~2.275 by 40,000 steps
- Shows smooth, consistent decline
2. **Geometric Distributions**:
- All λ values start above Uniform (~2.42–2.45 at 20k steps)
- Converge toward Uniform performance by ~35,000 steps
- λ=0.1 (purple) shows slowest convergence
- λ=0.9 (yellow) shows fastest convergence
- λ=0.5 (green) and λ=0.7 (light green) show intermediate convergence
**Right Chart Trends:**
1. **Uniform Distribution (Red Line)**:
- Maintains flat probability of ~0.25 across all UT steps
2. **Geometric Distributions**:
- λ=0.1 (purple): Starts at ~0.35, drops to ~0.2 by UT step 4
- λ=0.9 (yellow): Starts at ~0.9, drops to near 0 by UT step 4
- Higher λ values show steeper declines
- All geometric lines cross below Uniform probability by UT step 3
### Key Observations
1. **Training Loss Convergence**:
- Geometric models with λ > 0.5 outperform λ < 0.5 by 35,000 steps
- Uniform model maintains ~0.15 lower loss than initial geometric values
- All models show reduced variance in loss after 30,000 steps
2. **Distribution Probability Dynamics**:
- Higher λ geometric models exhibit greater initial confidence (probability)
- Confidence drops sharply for λ > 0.5 by UT step 3
- Uniform model maintains stable, moderate confidence
### Interpretation
The data demonstrates that geometric distributions with higher λ values (λ > 0.5) achieve faster convergence in training loss but exhibit higher initial confidence that rapidly declines. This suggests a trade-off between early performance and stability. The uniform distribution serves as a stable baseline with moderate performance and consistent confidence.
Notably, the geometric models' probability distributions show a "confidence correction" pattern - starting with overconfidence (high probability) that diminishes as training progresses. This aligns with the loss convergence pattern, where initial overestimation of model capability (high loss) improves over time.
The spatial relationship between the two charts reveals complementary insights: the left chart shows performance improvement over time, while the right chart reveals how confidence calibration evolves. The uniform model's stability in both metrics suggests it represents a well-calibrated, reliable baseline for comparison.