## Neural Network Diagram: Deep Reinforcement Learning Architecture
### Overview
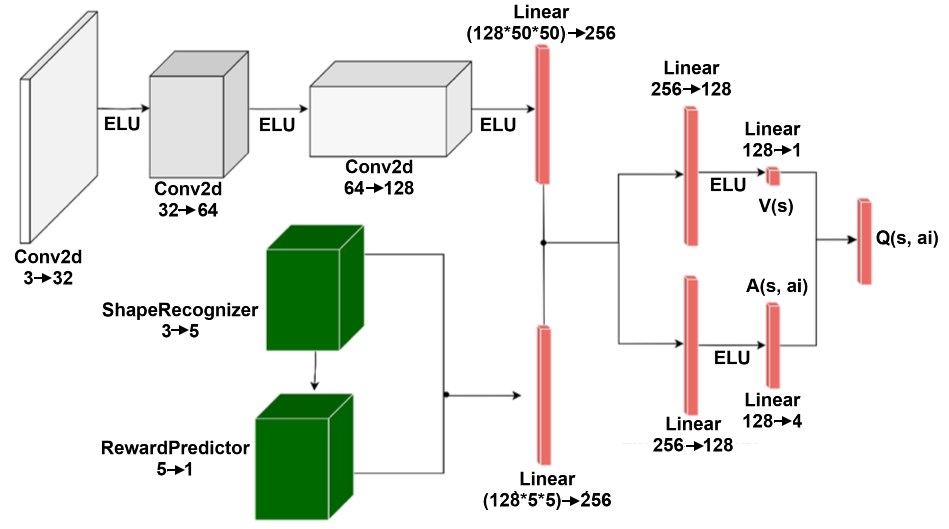
The image depicts a neural network architecture, likely used in a deep reinforcement learning context. It shows the flow of data through various convolutional (Conv2d) and linear layers, along with non-linear activation functions (ELU). The network appears to process visual input and predict both a value function V(s) and an advantage function A(s, ai), which are then combined to estimate the Q-value Q(s, ai).
### Components/Axes
* **Input:** A visual input (represented by a blank rectangle on the left).
* **Convolutional Layers (Conv2d):**
* Conv2d 3 -> 32
* Conv2d 32 -> 64
* Conv2d 64 -> 128
* **ShapeRecognizer:** 3 -> 5 (Green cube)
* **RewardPredictor:** 5 -> 1 (Green cube)
* **Linear Layers:**
* Linear (128\*50\*50) -> 256 (Red bar)
* Linear (128\*5\*5) -> 256 (Red bar)
* Linear 256 -> 128 (Red bar)
* Linear 128 -> 1 (Red bar)
* Linear 256 -> 128 (Red bar)
* Linear 128 -> 4 (Red bar)
* **Activation Function:** ELU (Exponential Linear Unit)
* **Value Function:** V(s)
* **Advantage Function:** A(s, ai)
* **Q-Value:** Q(s, ai)
### Detailed Analysis
The diagram shows two parallel pathways after the initial convolutional layers. The top pathway consists of three Conv2d layers with ELU activations in between. The bottom pathway consists of a ShapeRecognizer and a RewardPredictor.
The outputs of the two pathways are concatenated and fed into a Linear layer (128\*50\*50 -> 256 and 128\*5\*5 -> 256). This is followed by a Linear layer (256 -> 128). This layer splits into two pathways, one for estimating the value function V(s) and the other for estimating the advantage function A(s, ai).
* **Convolutional Layers:** The input image is processed by three convolutional layers. The first layer transforms the 3-channel input into a 32-channel representation. The second layer transforms the 32-channel representation into a 64-channel representation. The third layer transforms the 64-channel representation into a 128-channel representation.
* **ShapeRecognizer:** The ShapeRecognizer takes a 3-channel input and transforms it into a 5-channel representation.
* **RewardPredictor:** The RewardPredictor takes a 5-channel input and transforms it into a 1-channel representation.
* **Linear Layers:** The Linear layers perform linear transformations on the input data. The first Linear layer transforms the (128\*50\*50)-channel input into a 256-channel representation. The second Linear layer transforms the 256-channel representation into a 128-channel representation. The third Linear layer transforms the 128-channel representation into a 1-channel representation. The fourth Linear layer transforms the 128-channel representation into a 4-channel representation.
* **Value and Advantage Streams:** The 128-channel output is split into two streams. The first stream is fed into a Linear layer (128 -> 1) to estimate the value function V(s). The second stream is fed into a Linear layer (128 -> 4) to estimate the advantage function A(s, ai).
* **Q-Value Estimation:** The value function V(s) and the advantage function A(s, ai) are combined to estimate the Q-value Q(s, ai).
### Key Observations
* The network architecture combines convolutional layers for feature extraction with linear layers for value and advantage estimation.
* The use of ELU activations introduces non-linearity into the network.
* The network predicts both a value function and an advantage function, which are then combined to estimate the Q-value.
### Interpretation
This diagram illustrates a deep reinforcement learning architecture that likely aims to learn an optimal policy for an agent interacting with an environment. The convolutional layers extract relevant features from the visual input, while the ShapeRecognizer and RewardPredictor provide additional information about the environment. The value and advantage functions provide estimates of the expected return for different states and actions, which are then used to estimate the Q-value. The Q-value represents the expected return for taking a specific action in a specific state, and it is used to guide the agent's decision-making process. The architecture suggests a design that leverages both visual information and potentially learned representations of shapes and rewards to improve the agent's learning and performance.